Instant NGP(Inastan Neural Gaphics Primitives)는 2D 이미지를 입력하면 3D로 변환해 주는 딥러닝 모델인 NeRF를 발전시킨 모델 중 하나입니다.
original NeRF 모델 보다 학습 시간이 짧으면서 고품질로 3차원 재구성 결과를 얻을 수 있습니다.
또한 사용하기 편한 애플리케이션을 깃허브에 공개해 두었습니다.
이 글에서는 instant-ngp 깃허브에 공개된 애플리케이션 사용 방법에 대해 설명합니다.
instant-ngp 깃허브나 코드, 유튜브의 정보나 직접 확인해 본 내용들을 정리했습니다.
Instant Neural Gaphics Primitives 애플리케이션 설명
- neural graphics primitives를 사용하여 neural radiance fields (NeRF), signed distance functions (SDFs), neural images, and neural volumes 4가지를 구현
- multiresolution hash input encoding으로 MLP 학습 및 렌더링
- tiny-cuda-nn 프레임 워크 사용
GitHub - NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more
Instant neural graphics primitives: lightning fast NeRF and more - GitHub - NVlabs/instant-ngp: Instant neural graphics primitives: lightning fast NeRF and more
github.com
Instant NGP 데이터 준비
애플리케이션 동작을 확인하실 거라면 깃허브에 업로드된 테스트 데이터 셋을 사용하시면 됩니다.
직접 데이터 셋을 만든다면 instant ngp는 영상 이미지와 영상의 카메라 파라미터 데이터 입력이 필요하므로 영상을 촬영하고 해당 영상의 카메라 파라미터 데이터를 colmap이나 Record3D를 사용하여 추출하는 작업이 필요합니다.
영상 촬영
Instant NGP에서 영상 촬영 시 중요한 것들을 정리하면 다음과 같습니다.
- good coverage
- 이미지나 동영상 촬영 시에 연속된 프레임 간 너무 먼 거리에서 떨어져 촬영했다면 NeRF 학습 시 재구성이 어려울 수 있으니 촘촘히 찍을수록 좋은 결과를 얻을 수 있습니다.
- 물체의 주변을 돔으로 둘러쌓은 것처럼 주변을 조금씩 걸으면서 각 사진에 중첩된 부분이 많도록 찍고, 다양한 각도의 사진이 있는 것이 좋습니다.
- 좋은 퀄리티의 이미지
- blurry frames (motion blur와 defocus blur 모두)을 포함하지 않는 것이 좋습니다.
- 각 사진을 찍을 때 움직이지 않는 것이 좋습니다.
- still images가 video 보다 좋은데 좋은 카메라라도 video에서는 흐려지기 때문입니다.
- 정확한 카메라 파라미터
- Instant-ngp의 입력 데이터로 이미지와 함께 Colmap 등을 사용하여 추정한 카메라 파라미터가 함께 들어가야 하는데, 이때 잘못 레이블링 된 데이터는 성능에 악영향을 미칩니다.
- 좋은 결과를 얻기 위한 Colmap 가이드 (출처: https://colmap.github.io/tutorial.html).
- good texture : 완전히 텍스처가 없는 이미지(예: 흰 벽 또는 빈 책상)를 피하는 것이 좋습니다. 객체가 충분하지 않은 경우 포스터 등과 같은 추가 배경 개체를 배치할 수 있습니다.
- similar illumination : 유사한 조명 조건에서 이미지를 캡처. dynamic range 가 높은 장면(예: 그림자가 있는 태양을 배경으로 한 사진 또는 문/창을 통해 찍은 사진)이나 반짝이는 표면의 반사광을 피하는 것이 좋습니다.
- high visual overlap : 이미지 간 시각적으로 중첩이 많도록 촬영합니다. 각 객체가 최소 3개의 이미지에서 보이는 것이 좋습니다.
- different viewpoints : 다양한 viewpoint 에서 이미지 촬영합니다. 예를 들어 각 촬영 후 몇 걸음을 내딛는 것과 같이 카메라를 회전하기만 하여 같은 위치에서 이미지를 촬영하지 않는 것이 좋습니다.동시에 상대적으로 유사한 시점에서 많은 이미지를 얻는 것이 좋습니다.. 더 많은 이미지가 반드시 더 나은 것은 아니며 재구성 프로세스가 느려질 수 있습니다. 비디오를 입력으로 사용하는 경우 프레임 속도를 다운 샘플링하는 것을 고려합니다.
일반적인 Dataset의 문제들은 다음과 같은 게 있습니다.
- camera position의 잘못된 scale과 offset(가장 일반적)
- 이미지가 너무 적음
- 카메라 매개변수가 정확하지 않은 이미지(예: COLMAP가 실패하는 경우).
-> 이 경우 더 많은 이미지를 획득하거나 카메라 위치가 계산되는 프로세스를 조정해야 할 수 있음
카메라 파라미터 추출
Instant-ngp는 입력 데이터로 이미지와 각 이미지에 해당하는 카메라 파라미터 데이터가 필요한데 초기 카메라 parameters가 the original NeRF code base와 호환되는 형식의 transforms.json 파일로 입력되어야 합니다.
transforms.json 파일은 1) Colmap을 사용하거나 2)Record3D 사용하여 데이터 추출이 가능합니다.
1) COLMAP(Githup)
- COLMAP : Structure-from-Motion (SfM)이나 Multi-View Stereo (MVS) 파이프라인을 그래픽과 명령줄 인터페이스로 제공하는 소프트웨어입니다.
- scripts/colmap2nerf.py : instant-ngp 깃허브의 촬영한 일련의 사진 또는 비디오에서 데이터 세트를 생성하는 스크립트
- 스크립트 실행 시 FFmpeg 및 COLMAP이 실행되고 필요한 변환 단계를 거쳐 transforms.json형식으로 현재 디렉터리에 저장됩니다.
<colmap 파라미터 설명>
- video_fps
- Fram rate
- 비디오의 길이에 따라 50~ 150개의 이미지를 얻을 수 있도록 설정(1분 길이
의 비디오일 경우 2로 설정하는 것이 이상적)
- time_slice
- 비디오에서 이미지를 생성해야 하는 t1, t2 형식의 시간(초)
( time_slice '10,300''은 비디오의 10초에서 300초까지만 이미지를 생성)
- 비디오에서 이미지를 생성해야 하는 t1, t2 형식의 시간(초)
- colmap_matcher
- 사용할 matcher colmap을 선택
- 옵션 : exhaustive, sequential, spatial, transitive, vocab_tree
- colmap_camera_model
- Camera model
- 옵션 : SIMPLEINHOEWHOLEBIREMADA_RON_DIC(SID,SADALF
ISHEYE,RADIA_FISHEYE,OPENCY_FISHEYE
- colmap_camera_params
- 선택한 모델에 따른 고유 매개변수, (format: fx,fy,cx,cy,dist)
- images
- 이미지에 대한 입력 경로
- text colmap
- 텍스트 파일에 대한 입력 경로
- 옵션 : - run_colmap이 사용되는 경우 자동으로 설정됨)
- aabb_scale
- 장면의 범위를 지정
- 옵션 : 1,2,4,8,16,32,64,128
- Large scene scale 인수. (1=scene fits in unit cube, 2의 거듭제곱 128까지)
- aabb scale설명
instant-ngp specific parameter로 가장 중요한 파라미터입니다.
장면의 범위를 지정하며 기본 값은 1입니다.
카메라 위치를 원점으로 해당 값의 단위 거리에 있도록 장면의 크기가 조정됩니다.
원본 NeRF 데이터 세트와 같은 small synthetic scenes의 경우 기본 값을 사용하는 것이 좋습니다.
aabb_scale은 1이 이상적이며 가장 빠른 훈련이 가능합니다. NeRF 모델은 이미지가 이 bounding box 내에 포함된 장면이라고 가정하고 학습합니다. 그러나 natural scenes인 경우, 이미지에 bounding box 너머로 확장되는 배경이 있을 수 있는데 이것을 NeRF는 bounding box 외에 있는 "floaters "로 착각할 수 있으며 학습이 어렵습니다. aabb_scale 큰 2의 거듭제곱(최대 128까지)으로 설정 가능하며 이에 따라서 NeRF 모델은 ray를 더 큰 bounding box로 확장하여 학습합니다. 이는 훈련 속도에 약간의 영향을 미칠 수 있습니다. natural scenes의 경우 aabb_scale를 128부터 시작하여 가능하면 줄이기를 권장합니다. 이 값은 transforms.json 에서 직접 편집 가능합니다.
- skip_early
- Skip this many images from the start.
- keep_colmap_coords
- COLMAP의 원래 참조 프레임에 transforms.json을 유지
- 이렇게 하면 미리 보기 및 렌더링을 위해 장면의 방향 및 위치를 다시 지정
하지 않아도 됨).
- out Output path.
- vocab_path Vocabulary tree path.
2) Record3D
- Record3 D : ARKit에 의존하여 각 이미지의 카메라 포즈를 추정하는 iOS 앱
- 텍스처가 부족하거나 반복적인 패턴이 포함된 장면의 경우 COLMAP보다 더 강력합니다.
- scripts/record3d2nerf.py : instant-ngp 깃허브의 iPhone 12 Pro 이상(ARKit 기반)을 사용하여 Record3D으로 데이터 세트를 생성하는 스크립트
- iPhone 12 Pro를 사용하면 Record3D 를 사용하여 데이터를 수집하고 COLMAP을 사용하지 않을 수 있습니다.
Instant-NGP 애플리케이션 설명
Instant-NGP 애플리케이션을 실행하기 위해서는 instant-ngp.exe를 실행하고 data folder를 드래그합니다.
Instant-NGP 학습 시 주의할 점은 대부분은 NeRF 모델이 20초 정도 후에도 수렴되지 않으면 긴 훈련 시간 후에도 결과가 많이 향상되지 않습니다. large real world scenes의 경우 추가로 몇 분 동안 훈련하여도 약간의 추가적인 선명도만 얻을 수 있으며 거의 모든 수렴은 처음 몇 초 안에 발생하기 때문에 훈련 초기 단계에서 명확한 결과를 얻을 수 있도록 데이터를 조정하는 것이 좋습니다.
GUI에서 제공되는 기능들은 아래와 같습니다.
- 추가적인 features 학습 가능 - extrinsics과 intrinsics 최적화
- NeRF->Mesh과 SDF->Mesh 변환을 위한 Marching cubes*
- 비디오를 생성하기 위한 spline* 기반 camera 경로 편집기
- 모든 뉴런 입력 및 출력의 활성화 시각화를 디버깅합니다.
제가 instant-ngp를 사용할 당시에는 GUI의 각 설정 값들에 대한 설명을 찾지 못해서
아래의 설정값 설명들은 직접 확인했거나 깃허브 코드, 튜토리얼을 보고 정리했습니다.
Training 옵션 설명
<Training 부분>

<NeRF training options>
- Random bg color
- Optionally match nerf paper behavior and train on fixed
white bg. - We prefer training on random BG colors.
- Optionally match nerf paper behavior and train on fixed
- Snap to pixel centers
- Prior nerf papers don't typically do multi-sample anti-aliasing.
- So snap all pixels to the pixel centers.
- Near distance
- Set the distance from the camera at which training rays start
for nerf. - <0 means use ngp default
- Set the distance from the camera at which training rays start
- Loss
- L2/L1 / MAPE/SMAPE / Huber(default) / LogL1 / RelativeL2
- Depth Loss
- L2/L1 / MAPE/SMAPE/Huber(default) / LogL1 / RelativeL2
- RGB activation
- None / ReLU / Logistic(default) / Exponential
- Density activation
- None / ReLU / Logistic / Exponential(default)
Cone angle • exponential cone tracing* - 속도를 희생시키면서 품질을 약간 높임
- AABB가 1인 NeRF synthetic datasets에서 기본적으로 수행된
지만 더 큰 장면에서는 수행되지 않음
- None / ReLU / Logistic / Exponential(default)
Rendering 옵션 설명
<Rendering>
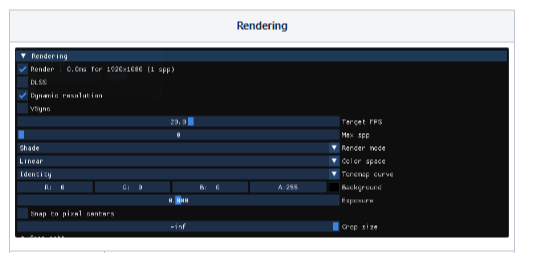
- DLSS
- toggling this on and setting "DLSS sharpening" below it to 1.0 can often improve
- render mode
- 1-AO/2-shade/3 - Nomals/4 - Positions/5 - Depth/6 - Distortion / 7 -Cost/8 - Slice
- Color space
- Prior nerf papers accumulate/blend in the sRGB color space. This messes not only
with background alpha, but also with DOF effects and the likes. - We support this behavior, but we only enable it for the case of synthetic nerf data
where we need to compare PSNR numbers to results of prior work. - NERF blends with background colors in sRGB space, rather than first transforming
to linear space, blending there, and then converting back. (See e.g. the PNG spec
for more information on how the alpha channel is always a linear quantity.) The
following lines of code reproduce NeRF's behavior (if enabled in testbed) in order
to make the numbers comparable. - Since sRGB conversion is non-linear, alpha must be factored out of it
- Linear /SRGB
- Prior nerf papers accumulate/blend in the sRGB color space. This messes not only
- Tonenap curve
- Identity (default) / ACES/ Hable / Reinhard
- Background
- 배경색 설정
- Exposure
- 이미지의 밝기를 제어
- 양수는 밝기를 증가시키고 음수는 감소
- Crop size
- size를 사용하여 boundin box 크기 설정 unit cube를 중심으로 Crop 됨
< Crop aabb >
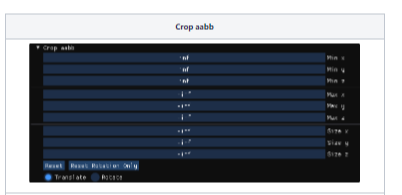
- Crop aabb
- instant-ngp의 NeRF 구현은 기본적으로 [0, 0, 0]에서 [1, 1, 1 ]까지의 unit bounding box에서만 ray
marching - 학습할 때 포커스하고 싶은 부분만 자를 수 있음.
- instant-ngp의 NeRF 구현은 기본적으로 [0, 0, 0]에서 [1, 1, 1 ]까지의 unit bounding box에서만 ray
Debug visualization 옵션 설명
< Debug visualization >
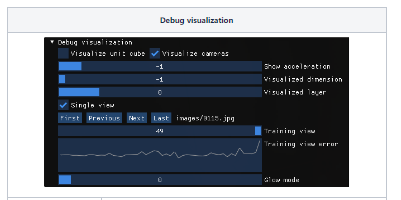
- Visualize unit cube
- instant-ngp NeRF 구현은 기본적으로 [0, 0, 0]에서 [1, 1, 1]까지의 unit bounding bax에서만 ray marching*함
- 데이터 로더는 입력 JSON 파일에서 camera transforms을 가져오고 입력 데이터의 원점을 이 큐브의 중심에 매핑하기 위해 positions = 0.33, offset = [0.5, 0.5, 0.5]로 조정
- scale factor는 원본 NeRF 논문의 synthetic datasets과 scripts/colmap2nerf.py 스크립트의 출력에 적합하도록 선택됨
- unit cube 외부에 배경이 보이는 natural scenes의 경우 transforms.json 파일의 aabb_scale를 2의 거듭 정수로 (최대 128)로 설정해야 함
- NGP에 로드할 때 수렴되지 않는 경우, 먼저 확인해야 할 것은 위에서 설명한 디버그 기능을 사용하여 unit cube에 대한 camera position
- Dataset이 주로 unit cube에 속하지 않으면 unit cube 재설정 필요
- transforms를 직접 수정하거나 전역 변수 선언
- Visualize cameras
- Camera data 시각화
→ Visualize unit cube와 Visualize cameras를 통해 Bounding box에 대한 Camera 정렬을 확인하는 것이 좋음
- Camera data 시각화
- Visualized dimension
- neural model layer의 multi-view visualization
- neural network에서 encode 된 각각의 dimension 시각화
- Multi resolution hash encoding 이 동작하는 것을 볼 수 있음
- 첫 dimension의 encode 결과는 low frequency detail를 커버하고 뒤의 dimension들은 high frequency detail을 인코딩
- Visualized layer
- 뉴런 네트워크의 각각의 layer 선택
- Single view
- First/Previous/Next/Last
- Training view
- 현재 모델의 Train data view
- Training view error
- 현재 모델의 Training view error 그래프
Camera 옵션 설명
< Camera >
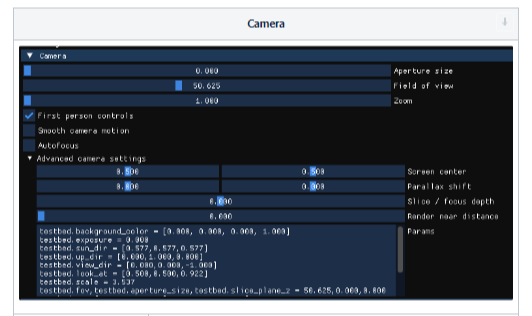
- Aperture size*
- 조리개 값
- Field of view*
- 시야각
- First-person controls
- 1인칭 컨트롤
- Smooth camera motion
- camera motion이 부드러워짐
- camera motion이 부드러워짐
< Snapshot >
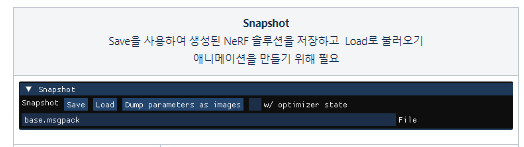
- Save
- 학습 후 이 snapshot을 저장(권장 확장자: .msgpack)
- Load
- 학습 전에 스냅샷을 로드(권장 확장자: .msgpack)
< Export mesh / volume / slices >
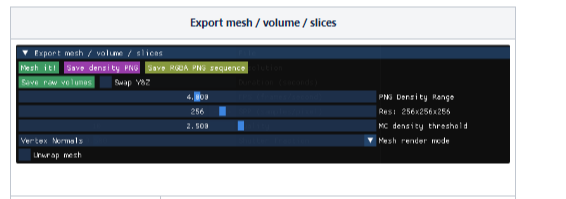
- Mesh it!
- NeRF 또는 SDF 모델에서 based mesh 기반 Mesh 출력
- OBJ 및 PLY 형식을 지원
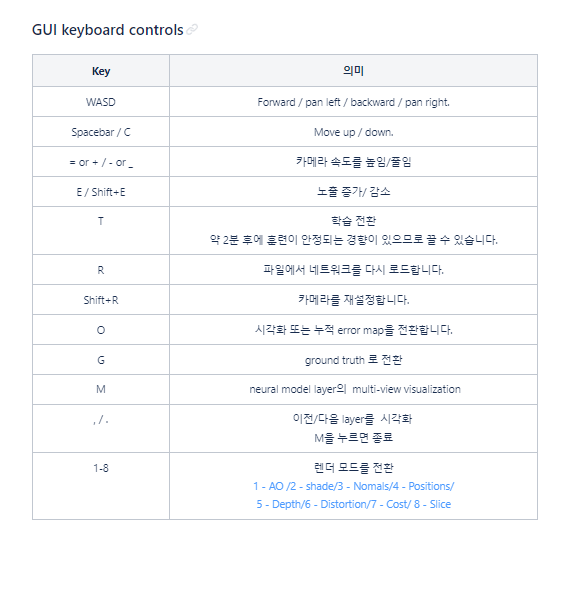
< Instant NGP GUI 키보드 컨트롤 >
Camera Path 옵션 설명
< Path manipulation >
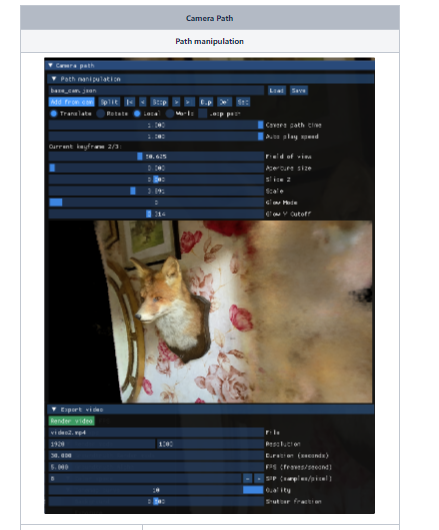
- video camera path
- render를 위한 카메라 path
- Add from cam
- cam (key frame을 추가하려면 scene을 탐색한 뒤 원하는 scene에서 Add from cam 은 클릭
- 각 cam 사이를 Bezier curves 카메라 궤적 생성
- read
- 생성했던 key frame 보기
- -stop: 자유롭게 이동하면서 설정했던 cam 위치 확인 가능
- |< / < / > / >|
- cam (key frame) 이동
- 선택한 cam의 xyz 숙이 나오고 이를 사용하여 cam 위치를 조정 가능
- Translate / Roate / Local/World*
- check 하여 cam 수정 가능
- Loop Path
- 마지막 key frame과 첫 번째 key frames을 연결시켜서 연속적인 loop 만듦
- split
- 선택한 cam과 다음 cam의 사이 cam 추가
- dup
- 선택한 cam 복사
- del
- 선택한 cam 삭제
- set
- 현재 scene으로 key frame (cam) 설정
- Current key frame
- 현재 선택한 key frame이 밑에 나옴
(현재 선택한 cam/전체 설정한 cam 개수)
- 현재 선택한 key frame이 밑에 나옴
- Field of view
- 시야각
- Aperture size
- 조리개 값
- Glow
- 빛이 발산하는 느낌을 줌. 광이 나는 효과
- 빛이 발산하는 느낌을 줌. 광이 나는 효과
< Export video >
- File
- File you can render a video.mp4 of your camera path or export the keyframes to a json file.
- Duration(seconds)
- Number of seconds the rendered video should be long.
- 비디오 길이
- FPS(frames/second)
- Number of frames per second.
- 1초당 보여주는 frame 이수
- SPP(samples/pixel)*
- Number of samples per pixel.
- A larger number means less noise, but slower rendering
- 빛을 추적하는 단위 픽셀 당 많은 빛을 추적할 경우 더 현실과 같은 이미지가 생성
- Quality
- rendering quality
- shutter fraction*
- 셔터 속도
- 셔터 속도
Instant-NGP 애플리케이션 실행 결과
손바닥 크기의 피규어를 1분 촬영하여 데이터 전처리 후 Instant-ngp로 학습하여 나온 3D결과를 동영상으로 저장해 보았습니다.
짧은 시간 학습하였고 이미지도 많이 사용하지 않았지만 잘 표현된 것 같습니다.
< 그래픽 용어 정리 >
- Ray Marching - 메시 데이터를 이용하는 기존의 3D 렌더링 방식과는 달리, 거리 함수(SDF)를 통해 오브젝트의 표면을 정의카메라로부터 스크린 픽셀들을 향해 레이를 전진시키고(Ray Marching), 해당 픽셀의 레이가 오브젝트 표면에 닿으면 그 픽셀에 오브젝트 표면을 렌더링 하는 방식을 사용.
(출처 : https://rito15.github.io/posts/ray-marching/) - Marching cube -마칭 큐브는 3차원 이산 스칼라 필드에서 등가곡면의 다각형 메쉬를 추출
- spline - 몇 개의 점을 기준으로 부드러운 곡선을 그리는 컴퓨터 그래픽스의 방법
- Pan Left / Pan Right - 영상 촬영에서의 Pan Left / Pan Right는 고정되어 있거나 안정적인 상태에서 카메라 축을 기준으로 왼쪽 또는 오른쪽 수평 방향으로 이동하며 촬영하는 샷.
- exposure - 메라에서 렌즈로 들어오는 빛을 셔터가 열려 있는 시간만큼 필름이나 건판에 비추는 것. 감도와 조리개값, 그리고 셔터 속도의 세 가지 개념의 조합으로 이루어지며, 사진의 밝기를 결정하는 아주 중요한 요소.
- Local / World(global) 좌표 - 오브젝트를 기준으로 한 상대 좌표 / 화면을 기준으로한 절대좌표
(출처 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=deux0083&logNo=220079476287) - Field of view - 시야 시야각 시야가 닿는 영역
- Aperture size - 조리개 값 -조리개는 사람의 눈에서 동공에 해당하며, 렌즈 안에 장착되어 통과하는 빛의 양을 조절하는 장치. 또한 조리개는 초점이 맞는 범위인 ‘심도(Depth of Field ; DOF)’에도 영향을 미침.
(출처 :https://post.naver.com/viewer/postView.nhn?volumeNo=27691656&memberNo=48373488) - glow mode - 빛이 발산하는 느낌을 줌, 광이 나는 효과
(출처 : https://learnopengl.com/Advanced-Lighting/Bloom) - SPP(samples/pixel) - 빛을 추적하는 단위 픽셀당 많은 빛을 추적할 경우 더 현실과 같은 이미지가 생성. spp가 감소하면 연산량은 줄어들지만, noise가 많은 이미지를 출력. 반대로 spp 증가하면 현실적인 이미지를 출력하지만, 연산량이 매우 많이 증가
(출처:https://koreascience.kr/article/JAKO201909358629468.pdf)https://m.blog.naver.com/renderday/221485971028) - shutter fraction - 셔터 속도는 카메라 셔터가 열려 있고 카메라 센서에 빛이 노출되는 시간. 카메라가 사진을 찍는 데 걸리는 시간.
(출처 :https://photographylife.com/what-is-shutter-speed-in-photography) - cone tracing :https://en.wikipedia.org/wiki/Cone_tracing


