파이썬을 사용하여 네이버 영화의 네티즌 평점과 리뷰 크롤링하고 csv 파일로 저장해봅니다
1. 필요한 패키지 불러오기 - requests, BeautifulSoup, time, csv
requests : HTTP 요청을 위해 사용하는 파이썬 라이브러리
BeautifulSoup : 웹 사이트에서 데이터를 추출하는 웹 스크래핑 라이브러리
time : 시간 데이터 처리 모듈
csv : CSV형식의 데이터를 읽고 쓰는 모듈
import requests
from bs4 import BeautifulSoup
import time
import csv
2. soup 객체 만들기
네이버 영화 리뷰 웹 페이지 구성 확인하기
데이터를 추출할 웹 페이지가 어떻게 구성되어 있는지 확인합니다.
아래의 네이버 영화에서는 네티즌의 리뷰와 평점이 게시되어있습니다.
https://movie.naver.com/movie/point/af/list.naver?&page=1
한 페이지에 10개의 리뷰가 있습니다.
다른 페이지를 불러오기 위해서는 URL의 마지막에 페이지 숫자를 바꿔줍니다.
2페이지-> https://movie.naver.com/movie/point/af/list.naver?&page=2
3페이지-> https://movie.naver.com/movie/point/af/list.naver?&page=3
soup 객체 만들기
for문으로 페이지 숫자를 증가해 가면서 soup 객체를 만들어 웹 페이지에서 HTML을 받아옵니다.
find_all는 지정한 조건의 태그의 내용을 모두 찾아 리스트로 반환합니다.
find_all('태그 이름', {'속성 이름': '속성 값' ...}) 형식으로 조건을 지정합니다.
tag가 td이고 class가 title인 태그를 riviews에 저장합니다.
한 페이지의 10개의 리뷰가 있으므로 10개의 리뷰 HTML이 reviews에 저장됩니다.
#page를 1부터 1씩 증가하며 URL을 다음 페이지로 바꿈
for page in range(1,500):
url = f'https://movie.naver.com/movie/point/af/list.naver?&page={page}'
#get : request로 url의 html문서의 내용 요청
html = requests.get(url)
#html을 받아온 문서를 .content로 지정 후 soup객체로 변환
soup = BeautifulSoup(html.content,'html.parser')
#find_all : 지정한 태그의 내용을 모두 찾아 리스트로 반환
reviews = soup.find_all("td",{"class":"title"})
3. 데이터 수집하기
수집하려는 데이터를 어떻게 html에서 가져올 수 있을지 확인합니다.
< 웹 페이지>

<HTML>
(F12개발자 도구-> Ctrl + Shift + C 누르고 커서를 사용해서 페이지의 찾고 싶은 요소 확인하기)

get과 get_text를 사용하여 setence - 리뷰, movie - 영화 제목, score- 평점을 저장합니다.
get - 지정한 태그의 모든 URL을 수집
get_text - 지정한 태그 아래의 텍스트를 문자열로 반환
#한 페이지의 리뷰 리스트의 리뷰를 하나씩 보면서 데이터 추출
for review in reviews:
sentence = review.find("a",{"class":"report"}).get("onclick").split("', '")[2]
#만약 리뷰 내용이 비어있다면 데이터를 사용하지 않음
if sentence != "":
movie = review.find("a",{"class":"movie color_b"}).get_text()
score = review.find("em").get_text()
review_data.append([movie,sentence,int(score)])
need_reviews_cnt-= 14. CSV 파일로 저장
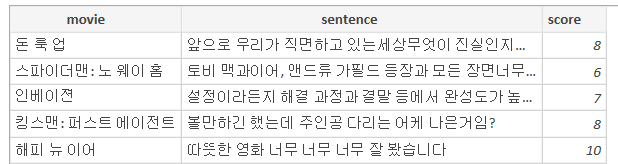
movie, sentence, score의 열의 데이터 형식으로 추출한 데이터를 저장합니다.
columns_name = ["movie","sentence","score"]
with open ( "samples.csv", "w", newline ="",encoding = 'utf8' ) as f:
write = csv.writer(f)
write.writerow(columns_name)
write.writerows(review_data)
< 저장된 CSV파일 결과 >
5. 다음 페이지를 조회하기 전 시간 두기
time 라이브러리의 sleep 함수를 사용하면 지정한 시간 동안 프로세스를 일시 정지할 수 있습니다.
time.sleep(0.5)
6. 전체 python 코드
import requests
from bs4 import BeautifulSoup
import time
import csv
need_reviews_cnt = 1000
reviews = []
review_data=[]
#page를 1부터 1씩 증가하며 URL을 다음 페이지로 바꿈
for page in range(1,500):
url = f'https://movie.naver.com/movie/point/af/list.naver?&page={page}'
#get : request로 url의 html문서의 내용 요청
html = requests.get(url)
#html을 받아온 문서를 .content로 지정 후 soup객체로 변환
soup = BeautifulSoup(html.content,'html.parser')
#find_all : 지정한 태그의 내용을 모두 찾아 리스트로 반환
reviews = soup.find_all("td",{"class":"title"})
#한 페이지의 리뷰 리스트의 리뷰를 하나씩 보면서 데이터 추출
for review in reviews:
sentence = review.find("a",{"class":"report"}).get("onclick").split("', '")[2]
#만약 리뷰 내용이 비어있다면 데이터를 사용하지 않음
if sentence != "":
movie = review.find("a",{"class":"movie color_b"}).get_text()
score = review.find("em").get_text()
review_data.append([movie,sentence,int(score)])
need_reviews_cnt-= 1
#현재까지 수집된 리뷰가 목표 수집 리뷰보다 많아진 경우 크롤링 중지
if need_reviews_cnt < 0:
break
#다음 페이지를 조회하기 전 0.5초 시간 차를 두기
time.sleep(0.5)
columns_name = ["movie","sentence","score"]
with open ( "samples.csv", "w", newline ="",encoding = 'utf8' ) as f:
write = csv.writer(f)
write.writerow(columns_name)
write.writerows(review_data)


