Jane Jacobs in the Sky: Predicting Urban Vitality with Open Satellite Data
Scepanovic, Sanja, et al. "Jane Jacobs in the Sky: Predicting Urban Vitality with Open Satellite Data." Proceedings of the ACM on Human-Computer Interaction 5.CSCW1 (2021): 1-25.
논문을 정리하고 번역한 글입니다.
논문 정리
도시활력이란?
- 도시 활력 = 하루 종일 보행자 활동
- 도시 활력이란 "위대한 미국 도시의 죽음과 삶"의 작가이자 활동가인 제인 제이콥스의 이론
- 1950년대 도시 계획 정책을 비판하며 미국의 많은 도시 이웃의 쇠퇴에 책임이 있다고 주장
- 모더니스트 도시 계획이 다양한 커뮤니티에서 인간 삶의 복잡성을 간과하고 지나치게 단순화한다고 문제를 제기
- Jane Jacobs는 공공질서를 유지하는 데 도움이 되는 통행인의 "거리에 대한 시선"과 함께 밀집된 복합 용도 개발과 걷기 좋은 거리, 도시의 활력을 옹호
- 도시 활력을 이론화하고 도시에서 삶의 촉진에 필요한 네 가지 조건이 있음을 발견
⓵토지 이용의 다양성 ⓶작은 블록 크기 ⓷ 경제 활동의 혼합 ⓸사람의 집중 - 건축가, 개발자, 도시 계획가 및 지역 사회 활동가의 사고에 엄청난 영향을 미침
문제점
- 도시 활력 이론의 중요성과 인기에도 불구하고 오랫동안 Jacobs의 이론은 대규모로 테스트될 수 없었음
이 연구를 위해서는 다양한 출처에서 세심하게 데이터를 수집해야 하고 많은 시간이 걸리기 때문 - ⓵토지 이용의 다양성 ⓶작은 블록 크기 ⓷ 경제 활동의 혼합 ⓸사람의 집중
- 이 네 가지 조건에 대한 프록시를 구축하고 궁극적으로 제인 제이콥스의 이론을 대규모로 테스트하기 위해 연구자들은 다양한 출처에서 비공개/공개 데이터를 모두 수집해야 했으며 수십 년이 걸렸음
이 논문에서 제안한 방법 - 위성 이미지와 딥러닝
- 공개적으로 사용 가능한 데이터 소스인 위성 이미지 한 가지만 사용하여 도시의 활력을 측정
- 데이터 수집 문제를 해결하기 위해 단일 소스(Sentinel-2 위성 이미지) 사용
1) 4가지 도시의 활력 조건을 먼저 예측한 다음 이를 사용하여 간접적으로 도시 활력을 예측
-> 4개의 조건 중 2개(⓵토지이용의 다양성 ⓶작은 블록 크기)는 육안으로 볼 수 있기 때문에 위성영상으로 식별할 수 있다고 가정
2) 도시의 활력을 직접적으로 예측
->이러한 이미지로부터 도시 활력을 직접적으로 예측할 수 있는지 연구
데이터 - 위성 이미지
- Sentinel-2 Level-2A data의 2018년도 이탈리아 6개의 도시 사진
- 유럽 우주국(ESA)이 지구 관측(EO) 데이터에 대한 액세스를 민주화한다는 목표로 만들어진 데이터
- Sentinel-2 의미 : 광학 이미지로 지표면 상태를 모니터링하고 토지피복 및 토지변화 감지 지도를 생성하
- Level-2A 의미 : 레벨은 처리 단계를 의미, 숫자가 높을수록 더 높은 처리 레벨, 레벨 2A레벨은 1C 제품 위에 대기 보정이 포함됨
- 3개의 True Color image (TCI) 대역(즉, B4, B3, B2)에 대해 10m의 동일한 공간 해상도로 정사 보정 및 생성
- 정사 보정이란?
항공사진 또는 위성 이미지 배율이 균일하도록 기하학적 보정 : 사진 또는 이미지가 주어진 다음 지도 투영. 보정되지 않은 항공사진과 달리 정사 사진은 지형 기복 , 렌즈 왜곡 및 카메라 기울기를 위해 조정된 지구 표면의 정확한 표현이기 때문에 실제 거리를 측정하는 데 사용 가능함(출처 :wikipedia)
- True Color image (TCI)
TCI 밴드 조합으로 Sentinel-2 데이터의 자연스러운 색상 표현 제공(출처 : Sentinel 공식 페이지)
방법론 - 특징 추출
<위성 이미지에서 지역 특징 추출을 위한 프레임워크>

1단계, 도시의 위성 이미지 Sentinel-2를 작은 이미지 조각(이미지 렛)으로 분할
2단계, 딥 러닝 특징 추출기를 사용하여 각 이미지렛에서 특징을 추출한 다음 PCA를 수행
3단계, 이미지릿 i는 해당 구역과 특징 벡터(vi)로 그룹화.
최종적으로 대표 구역 특징 벡터(xd)를 계산하기 위해 처리
2개의 특성 추출기 Feature Extractor 사용
1) CAE(Convolutional Auto Encoder) 특성 추출기

2) 사전 훈련된 CNN 특성 추출기
사전 훈련된 VGG16을 사용하여 위성 이미지에서 특징 z 세트를 추출
그런 다음 이러한 기능을 PCA가 있는 vCNN 구성 요소 집합으로 요약

Results
6개의 이탈리아 도시에서 그들의 프레임워크가 해당 기록에서 추출한 도시 활력의 분산의 평균 55%를 설명할 수 있음을 발견
Discussion and Conclusion
- 공개적으로 사용 가능한 Sentinel-2 이미지에서 특징을 추출하고 도시 활력 및 활력 자체에 대한 6가지 프록시를 예측하는 딥 러닝 프레임워크를 제안
- 실제적 시사점- 선진국의 도시 계획 개입 지원 , 빠르게 성장하는 개발 도상국의 지속 가능한 개발 이니셔티브
- 이론적 함의- 활력을 포착하는 시각적 특징을 배울 수 있으며, 이를 통해 다양한 자연 및 문화 환경에서 생명력이 표현되는 방식의 미묘함을 발견함
Limitations
- Sentinel-2 데이터 세트의 개방성은 장점이지만 제한된 공간 해상도가 한계 - 더 높은 공간 해상도 데이터를 공개적으로 사용할 수 있다면 모델의 성능이 향상될 것
- 휴대전화 데이터와 위성 데이터 사이의 시간차(이 경우 3년). - 이 기간 동안 도시 활력의 일부 측면이 변경될 수 있음
- 이 연구는 이탈리아 맥락에서만 수행되었기 때문에 일반화 가능성에 의문을 제기할 수 있음
- 모델은 주로 (실제보다는) 활력 가능성을 포착하고 있으며, 드물기는 하지만 특정 상황에서 예측이 실제 활력 수준과 일치하지 않을 수 있음 (예를 들어, COVID-19 전염병이 완전히 폐쇄된 동안 밀라노의 위성 이미지를 촬영한 경우 모델은 여전히 평상시와 유사한 활력 수준을 예측할 것)
논문 번역
아래 글은 논문을 번역한 내용입니다.
제목 : 하늘의 제인 제이콥스: 개방형 위성 데이터로 도시 활력 예측
도시 전체에 걸쳐 사람들의 존재
흔히 '도시의 활력'이라고 불리는 하루는 세계적 수준의 도시가 가장 열망하는 자질 중 하나이지만 달성하기 가장 어려운 것 중 하나입니다. 1970년대로 돌아가서 Jane Jacobs는 도시 활력을 이론화하고 도시에서 삶의 촉진을 위해 요구되는 네 가지 조건이 있음을 발견했습니다: 토지 이용의 다양성, 작은 블록 크기, 경제 활동의 혼합, 사람들의 집중. 이 네 가지 조건에 대한 프락시를 구축하고 궁극적으로 제인 제이콥스의 이론을 대규모로 테스트하기 위해 연구자들은 다양한 출처에서 개인 데이터와 공개 데이터를 모두 수집해야 했으며 수십 년이 걸렸습니다. 여기에서 우리는 공개적으로 사용할 수 있는 단일 데이터 소스인 Sentinel-2 위성 이미지의 사용을 제안합니다.
특히 처음 두 가지 조건(토지이용의 다양성과 작은 블록 크기)은 위성영상에서 육안으로 확인이 가능하기 때문에 최첨단 딥러닝 프레임워크로 자동 추출이 가능한지, , 결국 추출된 특징은 활력을 예측할 수 있습니다. 통화 데이터 기록이 있는 이탈리아 6개 도시에서 우리의 프레임워크가 해당 기록에서 추출한 도시 활력의 분산을 평균 55% 설명할 수 있음을 발견했습니다.
1. 소개
살기 좋은 도시는 삶으로 가득 찬 곳이며 그 삶은 도시 거주자들에 의해 만들어집니다 [37, 42]. 작가이자 활동가인 Jane Jacobs는 1961년 그녀의 책 "The Death and Life of Great American Cities"에서 도시 활력(즉, 하루 종일 보행자 활동)의 네 가지 "생성자"를 식별했습니다. 토지 사용의 다양성, 작은 블록 크기, 혼합 경제 활동, 그리고 사람들의 집중. 그들 없이는 도시가 죽을 것입니다. 그들과 함께 그것은 번성할 것입니다. 그녀의 아이디어는 건축가, 개발자, 도시 계획가 및 지역 사회 활동가의 생각에 엄청난 영향을 미쳤습니다. 그 중요성과 인기에도 불구하고 오랫동안 Jacobs의 이론은 대규모로 테스트될 수 없었습니다. 다양한 출처에서 민간 및 공공 데이터를 수집한 결과, 4개의 발전기에 대한 가설된 효과는 한국 서울[56]과 이탈리아 6개 도시[14]에서 최근에야 테스트되었습니다. 그러나 이 모든 연구는 다양한 출처에서 세심하게 데이터를 수집했으며, 이는 수년(서울의 경우 10년)이 소요되어 연구 발전을 상당히 제한했습니다.
데이터 수집 문제를 해결하기 위해 우리는 Sentinel-2 위성 이미지[58]라는 단일 소스에서 도시 활력(및 활력 자체)의 4가지 생성기 중 일부를 추정할 수 있는지 여부를 조사했습니다. 4개의 발전기 중 2개(토지 용도의 다양성과 작은 블록 크기)는 육안으로 볼 수 있으므로 위성 이미지에서 식별할 수 있다고 가정했습니다. 우리는 또한 그러한 이미지에서 활력을 직접 예측할 수 있는지 연구했습니다. 활력 생성기를 먼저 예측한 다음 간접적으로 활력을 예측하거나 직접 활력을 예측하는 두 가지 예측 작업 모두 위성 데이터에 대해 수행할 수 없다는 것은 분명하지 않습니다. 그 이유를 알아보려면 그림 1을 고려하십시오. 이탈리아 6개 도시의 대표적인 위성사진은 비슷한 활력 수준의 지역에서 왔더라도 현저하게 다른 시각적 특징(예: 도시 및 자연 형태의 색상 및 다양성)을 나타냅니다.

그림 1. 이탈리아 6개 도시 각각에서 가장 높은 활력 수준과 가장 낮은 활력 수준을 가진 지역에 대한 위성 보기의 예. 비슷한 활력 수준을 가지고 있음에도 불구하고 표시된 지역은 매우 다른 도시 형태를 나타냅니다.
우리는 3개의 모듈로 구성된 처리 프레임워크를 구축했으며, 각 모듈은 다음과 같습니다. i) 위성 이미지(이미지렛이라고 함)에서 작은 이미지를 추출합니다. ii) 최첨단 딥 러닝 방법을 사용하여 이러한 이미지릿에서 시각적 특징을 추출합니다. iii) 이러한 특징을 지구 수준의 특징 벡터로 결합합니다. 그렇게 함으로써 우리는 두 가지 주요 기여를 할 수 있었습니다.
C1 우리는 공개적으로 사용 가능한 Sentinel-2 위성 이미지를 기반으로 도시 지역의 대표적인 특징 벡터를 추출하는 딥 러닝 프레임워크를 기반으로 두 가지 기술을 구축했습니다(섹션 3).
C2 우리는 이러한 구역 특징 벡터로부터 토지 이용 및 소규모 블록 크기에 대한 프락시를 예측할 수 있을 뿐만 아니라 도시 활력을 직접 예측할 수 있음을 보여주었습니다(섹션 4). 5중 교차 검증 실험에서 우리는 위성 기능이 평균적으로 이탈리아 6개 도시에 걸쳐 도시 활력에 대한 분산의 55% 이상을 설명한다는 것을 발견했습니다. 모델이 일반화되면 우리는 "leave-one-city" 검증을 수행했습니다(모델이 도시 집합에서 훈련되고 보이지 않는 도시에서 테스트됨). 이 실험에서 우리는 모델이 최대 50개까지 설명할 수 있음을 발견했습니다. 밀라노의 경우 %, 플로렌스의 경우 61%로, 우리 방법이 보이지 않는 도시로 일반화할 수 있음을 시사하지만 일부 도시에서는 이 성능이 로마의 경우 최대 25%까지 떨어지는 것으로 나타났습니다. 철저한 조사를 통해 우리는 다음을 식별했습니다. 도시의 고유한 자연적, 문화적, 역사적 맥락을 포함하여 로마에서의 성능 저하에 대한 잠재적인 이유 따라서 우리는 향후 작업에 대한 권장 사항을 논의합니다(섹션 5).
이 작업은 소셜 컴퓨팅과 도시 분석의 두 연구 영역이 교차하는 지점에 있습니다. 이 둘을 결합하면 인공위성 이미지와 같은 새로운 데이터 소스를 사용하여 계산 방식으로 사회 과학의 일반적인 질문에 답할 수 있습니다.
미래 작업을 위한 새로운 기회를 열어줍니다(섹션 5). 프로젝트 웹 페이지는 https://goodcitylife.org/vitality에서 사용할 수 있습니다.
2 관련 작업
이 연구와 관련된 세 가지 주요 연구 라인이 있습니다. 첫째, 도시 활동을 정량화하는 소셜 컴퓨팅 연구. 둘째, Jane Jacob의 4가지 도시 활력 생성기를 대규모로 테스트한 연구입니다. 셋째, 인공위성 영상에서 육안으로 볼 수 없는 미묘한 도시 속성(예: 범죄율, 부동산 가격)을 자동으로 추론하는 연구.
2.1 소셜 미디어 데이터에서 도시 활동 측정 소셜 컴퓨팅 연구 커뮤니티에서 연구자들은 다양한 관점에서 도시 활동을 정량화하기 위해 노력했습니다. 예를 들어, 그들은 도시 위치의 아름다움, 고요함, 행복에 대한 사람들의 인식을 크라우드 소싱하고 [46], 이러한 크라우드 소싱 결과를 지리적 참조 소셜 미디어 콘텐츠(예: Flickr 사진)와 결합하여 구축했습니다. 도시에서 아름답고 조용하거나 행복한 도시 경로를 제안하는 경로 추천 시스템 [44, 46, 60]. Le Falher et al. [35] Foursquare 체크인을 사용하여 도시 이웃을 일반적인 활동 유형(예: 식사, 문화, 쇼핑)으로 분류했습니다. De Choudhury et al. [13]은 사진 업로드 패턴을 기반으로 개별 관광객의 움직임을 식별하고 해당 위치에서 보낸 평균 시간과 위치 인기도가 흥미로운 경로의 두 가지 유용한 예측 변수임을 발견했습니다.
연구자들은 공개적으로 사용 가능한 소셜 미디어 데이터를 사용하여 도시 역학을 연구했습니다. 예를 들어, Araujo et al. [3] 최근 Facebook 마케팅 API를 사용하여 도시 지역을 인구 통계학적으로 프로파일링 했습니다. Redi et al. [47]은 해당 지역의 Flickr 이미지에서 해당 지역의 분위기를 예측했습니다. Venerandi et al. 은 전통적으로 인구 조사 데이터에서 파생되었고 얻는 데 비용이 많이 들었던 결핍 지수를 보완하기 위해. [61] Foursquare 및 OpenStreetMap 데이터를 사용했습니다. 이 모든 작업 뒤에 있는 전제는 위치 기반 서비스의 사용자 생성 콘텐츠가 풍부한 행동 추적으로 변환된다는 것입니다 [13, 19, 63]. 보다 일반적으로 소셜 컴퓨팅 커뮤니티에서 새로운 기술로 도시, 이웃 및 지역 커뮤니티에 권한을 부여해야 할 필요성이 오랫동안 인식되어 왔습니다 [12]. 비슷한 맥락에서 우리의 작업은 공개적으로 사용 가능한 데이터를 사용하여 도시 활력의 주요 측면을 수량화하는 프레임워크를 개발합니다.
2.2 제인 제이콥스의 인사이트를 실증적으로 검증하기 가계 여행 설문조사는 서울시 전체의 걷기와 운전 활동을 수집하고 5년에 한 번 실시합니다. Sung et al. [56]은 2010년 설문조사를 통해 도시활력을 운용화한 결과, 서울의 소규모 행정구역인 동 전체에 걸쳐 도시활력의 4개 동력이 유지되는 것으로 나타났다. 비슷한 설정에서 6개의 이탈리아 도시에서 De Nadai et al. [14]는 4개의 생성기가 이탈리아어 콘텍스트에도 적용된다는 것을 발견했습니다. 연구원들은 값비싼 다년간의 조사 대신 휴대전화 인터넷 밀도를 도시 활동의 대용물로 사용했습니다. 마지막으로, 도시의 활력을 넘어 연구자들은 범죄에 대한 예측 모델을 구축하기 위해 Jacobs의 자연 감시 아이디어를 광범위하게 활용했습니다. 보행자 활동은 "자연 감시" 역할을 하여 범죄율을 감소시킵니다 [6, 7, 59].
2.3 위성 영상에서 도시 변수 추론 위성 영상은 최근 위성 영상 연구에서 보여주듯이 다양한 도시 과정을 인코딩하는 지역의 전체 구조를 포착합니다. 예를 들어 Han et al. [26]은 전국 지역의 고해상도 위성 이미지를 고정 크기의 지역 수준 특징 벡터로 매핑하는 딥 러닝 아키텍처를 개발했습니다. 그런 다음 저자는 이러한 특성을 사용하여 인구 밀도, 인구 연령 분포, 가구 수 및 크기, 1인당 소득과 같은 지역의 사회 경제적 특성을 예측할 수 있음을 보여주었습니다. Albert et al. [1]은 Google 지도의 고해상도 위성 이미지를 사용하여 도시 지역의 토지 사용 패턴을 연구했습니다. 이미지에 레이블을 지정하기 위해 저자는 300개의 유럽 도시에 걸쳐 20개의 토지 사용 등급으로 토지 분류를 제공하는 Urban Atlas에 의존했습니다. 주어진 위치에 대해 두 개의 심층 컨볼루션 신경망인 ResNet [27]과 VGG-16 [52]을 훈련시켜 224 × 224 이미지에 대해 가장 가능성이 높은 클래스를 예측했습니다.
달성된 분류 정확도는 0.7에서 0.8 사이였습니다. 또한 Albert et al. 모델이 한 도시의 이미지로 훈련되어 완전히 다른 도시의 클래스를 예측할 수 있음을 보여주었습니다. Law et al. [34]는 위성/항공 이미지가 주택 가격 예측을 향상할 수 있는지 여부를 연구했습니다. 저자는 Bing에서 관심 부동산 주변의 고해상도 위성/항공 이미지를 얻었고, 반 해석 가능한 방식으로 위성 이미지에서 추출한 기능을 통합하여 주택 가격을 예측하기 위한 표준 헤도닉 가격 접근 방식을 개선할 수 있음을 보여주었습니다.
Albert et al. [2]는 위성 데이터에서 인구, 광도(에너지 접근 및 사용에 대한 프락시) 및 건물 밀도와 같은 주요 도시 거시경제 변수의 분포를 연구했습니다. 전 세계적으로 인구가 10,000명 이상인 모든 도시에서 저자는 조명 수준의 공간 분포(이전에 에너지 접근 및 자산 수준[29]에 대한 프락시로 표시됨)와 인구 집중 사이의 강력한 연관성을 보여주었습니다. Albert et al. [2]는 저자들이 도시 활력의 대용물인 인구 밀도와 건설 기반 시설을 연구했다는 점에서 우리와 유사합니다. 그러나 Albert et al. 두 가지 주요 면에서 우리와 다릅니다. i) 이것이 초점이 아니었기 때문에 도시 활력의 이론적 개념의 조작 화가 없습니다. ii) 저자는 25,000개의 도시를 대략적인 수준(750m - 1km/px의 공간 해상도에서 TerraSar 및 LandScan 데이터 사용)으로 연구했지만, 이 현재 작업에서는 훨씬 더 미세한 수준의 도시에서 작업할 수 있었습니다. 세부 정보(10m/px의 공간 해상도에서 Sentinel-2 데이터 포함).
Wang et al. [62]는 해당 지역의 장소에 대한 온라인 리뷰 수와 관련된 도시 지역의 상업적 활성을 위성 데이터(및 스트리트 뷰)에서 예측할 수 있는지 여부를 연구했습니다. Wang et al. 위성 이미지에서 특징을 추출하고 이러한 특징을 회귀 방법에 공급하는 파이프라인이 사용되었다는 점에서 우리와 유사합니다. 그러나 우리의 현재 연구와 비교하여 두 가지 주요 차이점이 있습니다. I) 도시 활력에 대한 조사가 없고 그 구성 요소 중 하나인 상업적 활성만 있습니다. 및 ii) Wang et al. 우리가 사용한 공개적으로 사용 가능한 Sentinel-2 이미지와 비교하여 작업은 상업용 위성 이미지를 사용했습니다. 데이터의 상업적 특성은 특히 개발도상국의 경우 소셜 컴퓨팅 커뮤니티의 포괄성 측면에서 장애물을 만들 수 있습니다.
요약하면, 이전 연구에서는 위성 데이터를 사용하여 인구 밀도, 상업 활동 및 도시 활력에 영향을 미치는 기타 변수를 측정했지만 활력에 직접 초점을 맞춘 연구는 없었습니다. 또한 이전 작업의 대부분은 우리와 같이 공개적으로 사용 가능한 Sentinel 이미지 대신 Bing 및 Google Earth와 같은 상업용 위성 이미지를 사용했습니다. Sentinel과 같이 공개적으로 사용 가능한 위성 데이터를 기반으로 이 작업을 수행함으로써 다른 액세스 제어 및 값비싼 데이터 세트를 기반으로 하는 방법과 동등한 성능으로 구축된 환경(예: 활력)에 대한 통찰력을 체계적으로 도출할 수 있음을 보여줍니다. 이는 Sentinel과 다른 데이터 세트 간의 공간 해상도 차이에도 불구하고 마찬가지입니다. 우리는 이것이 커뮤니티가 특히 세계의 개발 도상국에서 후속 연구를 수행할 수 있는 권한을 더욱 강화할 수 있을 것으로 예상합니다.
2.3 위성 영상에서 도시 변수 추론 위성 영상은 최근 위성 영상 연구에서 보여주듯이 다양한 도시 과정을 인코딩하는 지역의 전체 구조를 포착합니다. 예를 들어 Han et al. [26]은 전국 지역의 고해상도 위성 이미지를 고정 크기의 지역 수준 특징 벡터로 매핑하는 딥 러닝 아키텍처를 개발했습니다. 그런 다음 저자는 이러한 특성을 사용하여 인구 밀도, 인구 연령 분포, 가구 수 및 크기, 1인당 소득과 같은 지역의 사회 경제적 특성을 예측할 수 있음을 보여주었습니다. Albert et al. [1]은 Google 지도의 고해상도 위성 이미지를 사용하여 도시 지역의 토지 사용 패턴을 연구했습니다. 이미지에 레이블을 지정하기 위해 저자는 300개의 유럽 도시에 걸쳐 20개의 토지 사용 등급으로 토지 분류를 제공하는 Urban Atlas에 의존했습니다. 주어진 위치에 대해 두 개의 심층 컨볼루션 신경망인 ResNet [27]과 VGG-16 [52]을 훈련시켜 224 × 224 이미지에 대해 가장 가능성이 높은 클래스를 예측했습니다.
달성된 분류 정확도는 0.7에서 0.8 사이였습니다. 또한 Albert et al. 모델이 한 도시의 이미지로 훈련되어 완전히 다른 도시의 클래스를 예측할 수 있음을 보여주었습니다. Law et al. [34]는 위성/항공 이미지가 주택 가격 예측을 향상할 수 있는지 여부를 연구했습니다. 저자는 Bing에서 관심 부동산 주변의 고해상도 위성/항공 이미지를 얻었고, 반 해석 가능한 방식으로 위성 이미지에서 추출한 기능을 통합하여 주택 가격을 예측하기 위한 표준 헤도닉 가격 접근 방식을 개선할 수 있음을 보여주었습니다.
Albert et al. [2]는 위성 데이터에서 인구, 광도(에너지 접근 및 사용에 대한 프락시) 및 건물 밀도와 같은 주요 도시 거시경제 변수의 분포를 연구했습니다. 전 세계적으로 인구가 10,000명 이상인 모든 도시에서 저자는 조명 수준의 공간 분포(이전에 에너지 접근 및 자산 수준[29]에 대한 프락시로 표시됨)와 인구 집중 사이의 강력한 연관성을 보여주었습니다. Albert et al. [2]는 저자들이 도시 활력의 대용물인 인구 밀도와 건설 기반 시설을 연구했다는 점에서 우리와 유사합니다. 그러나 Albert et al. 두 가지 주요 면에서 우리와 다릅니다. i) 이것이 초점이 아니었기 때문에 도시 활력의 이론적 개념의 조작 화가 없습니다. ii) 저자는 25,000개의 도시를 대략적인 수준(750m - 1km/px의 공간 해상도에서 TerraSar 및 LandScan 데이터 사용)으로 연구했지만, 이 현재 작업에서는 훨씬 더 미세한 수준의 도시에서 작업할 수 있었습니다. 세부 정보(10m/px의 공간 해상도에서 Sentinel-2 데이터 포함).
Wang et al. [62]는 해당 지역의 장소에 대한 온라인 리뷰 수와 관련된 도시 지역의 상업적 활성을 위성 데이터(및 스트리트 뷰)에서 예측할 수 있는지 여부를 연구했습니다. Wang et al. 위성 이미지에서 특징을 추출하고 이러한 특징을 회귀 방법에 공급하는 파이프라인이 사용되었다는 점에서 우리와 유사합니다. 그러나 우리의 현재 연구와 비교하여 두 가지 주요 차이점이 있습니다. I) 도시 활력에 대한 조사가 없고 그 구성 요소 중 하나인 상업적 활성만 있습니다. 및 ii) Wang et al. 우리가 사용한 공개적으로 사용 가능한 Sentinel-2 이미지와 비교하여 작업은 상업용 위성 이미지를 사용했습니다. 데이터의 상업적 특성은 특히 개발도상국의 경우 소셜 컴퓨팅 커뮤니티의 포괄성 측면에서 장애물을 만들 수 있습니다.
요약하면, 이전 연구에서는 위성 데이터를 사용하여 인구 밀도, 상업 활동 및 도시 활력에 영향을 미치는 기타 변수를 측정했지만 활력에 직접 초점을 맞춘 연구는 없었습니다. 또한 이전 작업의 대부분은 우리와 같이 공개적으로 사용 가능한 Sentinel 이미지 대신 Bing 및 Google Earth와 같은 상업용 위성 이미지를 사용했습니다. Sentinel과 같이 공개적으로 사용 가능한 위성 데이터를 기반으로 이 작업을 수행함으로써 다른 액세스 제어 및 값비싼 데이터 세트를 기반으로 하는 방법과 동등한 성능으로 구축된 환경(예: 활력)에 대한 통찰력을 체계적으로 도출할 수 있음을 보여줍니다. 이는 Sentinel과 다른 데이터 세트 간의 공간 해상도 차이에도 불구하고 마찬가지입니다. 우리는 이것이 커뮤니티가 특히 세계의 개발 도상국에서 후속 연구를 수행할 수 있는 권한을 더욱 강화할 수 있을 것으로 예상합니다.
3 DATA AND METHODS
이 섹션에서는 각 도시의 구역이 구역 특성 벡터로 인코딩 된 다음 구역의 도시 활력 값과 연결되는 방법을 설명합니다. 먼저 위성 이미지에서 작은 이미지 조각(이미지릿)을 추출하고 딥 러닝 특징 추출기를 사용하여 구문 분석하여 이미지릿 특징 벡터를 생성했습니다(3.1절). 둘째, Urban Atlas, Open Street Map, 휴대폰 데이터(섹션 3.2)를 포함한 다양한 데이터 소스를 결합하여 해당 지역의 도시 활력을 계산했습니다. 마지막으로 지구를 구성하는 이미지릿에 해당하는 이미지릿 특징 벡터를 결합하여 지구의 특징 벡터를 생성하고 결과 지구 특징 벡터를 이전에 계산된 지구의 도시 활력 값과 연결했습니다(3.3절).
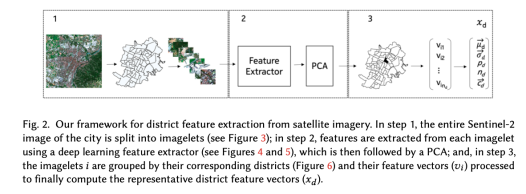
그림 2. 위성 이미지에서 지역 특징 추출을 위한 프레임워크. 1단계에서 도시의 전체 Sentinel-2 이미지는 이미지렛으로 분할됩니다(그림 3 참조). 2단계에서 딥 러닝 특징 추출기를 사용하여 각 이미지렛에서 특징을 추출한 다음(그림 4 및 5 참조) PCA가 뒤따릅니다. 3단계에서 이미지릿 i는 해당 지역(그림 6)과 특징 벡터(vi) 별로 그룹화되어 최종적으로 대표 지역 특징 벡터(xd)를 계산합니다.
3.1 Creating Imagelet Feature Vectors from Satellite Images
2014년에 유럽 우주국(ESA)은 지구 관측(EO) 데이터에 대한 액세스를 민주화하는 것을 목표로 하는 Copernicus1 프로그램[58]의 일환으로 첫 번째 Sentinel 위성을 발사했습니다. 이러한 수십억 달러의 투자 덕분에 오늘날 우리는 레이더(Sentinel-1, Sentinel-3), 고도계(Sentinel-3) 및 광학(Sentinel-2) 센서에서 정확하고 시기적절한 육상 위성 데이터에 자유롭게 액세스 할 수 있습니다. Sentinel 시리즈의 다른 위성은 대기 및 해양 데이터를 제공합니다. Copernicus와 같은 프로그램의 목표는 매우 야심적입니다. 여기에는 환경 관리, 기후 변화의 영향 완화 지원, 농업 모니터링, 도시 개발 지원[51] 등이 포함됩니다.
3.1.1 Sentinel-2 이미지.
이 연구를 위해 지표면 상태를 모니터링하고 토지 피복 및 토지 변화 감지 지도를 생성하는 역할을 하는 Sentinel-2 광학 이미지를 사용했습니다 [17]. 광학 센서(Multi-Spectral Instrument [9])는 10m에서 60m의 공간 해상도 범위에 있는 13개의 스펙트럼 대역(B1-B13)을 감지합니다. Sentinel-2 이미지가 배포되는 여러 처리 수준 중에서 Level-1C 및 Level-2A는 대중에게 무료로 제공됩니다. Level-2A는 더 높은 처리 수준이며 Level-1C 제품 위에 대기 보정[39]이 포함됩니다. 또한 이 제품의 이미지는 정위(측지 좌표로 투영)되고 3개의 소위 트루 컬러 이미지(TCI) 대역(즉, B4, B3, B2)에 대해 10m의 동일한 공간 해상도로 생성됩니다. TCI 밴드 조합은 Sentinel-2 데이터의 자연스러운 색상 표현을 제공하며 [22] 토지 피복 연구[54]에 널리 사용됩니다. 그 풍부함과 이러한 모든 필요한 전처리 단계가 이미 수행되었다는 점을 감안할 때 우리는 이 연구를 위해 레벨 2A 제품을 선택했습니다. 우리는 2018년부터 선정된 6개의 이탈리아 도시에 대해 Sentinel-2 Level-2A 제품을 다운로드했습니다(즉, 이 제품이 2018년에 운영되기 시작한 이후 가장 빠른 제품). 모든 이미지는 WGS 84 / UTM 영역 32N 측지 좌표 참조 시스템(CRS)으로 다시 투영되었으며 때로는 EPSG:32632로도 표시됩니다. 이 CRS는 북반구 6°E와 12°E 사이 및 이탈리아를 포함하는 적도와 84°N 사이에서 사용하기에 적합합니다.
3.1.2 이미지렛 전처리 및 생성.
훈련 데이터를 생성하기 위해 각 도시에 대해 Sentinel-2 이미지를 세 단계로 처리했습니다(그림 3).
(1) TCI 대역(B4, B3, B2)에서 지리 참조 래스터 이미지를 생성했습니다.
(2) 도시 경계를 기반으로 이미지를 자릅니다(공식 모양 파일에서 파생됨). 그리고
(3) 자른 이미지를 64 × 64 픽셀 크기의 이미지렛으로 분할합니다.
이 이미지릿 크기는 결과 이미지릿이 학군의 크기(표 1)에 비해 너무 크지 않고 최종 해상도 측면에서 너무 작지 않도록 선택되었지만 딥 러닝 프레임워크( 섹션 3.1.3). 사전 처리를 통해 6개 도시에서 총 9,115개의 이미지렛이 생성되었습니다.
표 1. 구역 수(Nc), 평균 크기(km2) 및 인구, 도시다 획득한 이미지렛 수.
3.1.3 딥 러닝 특징 추출기.
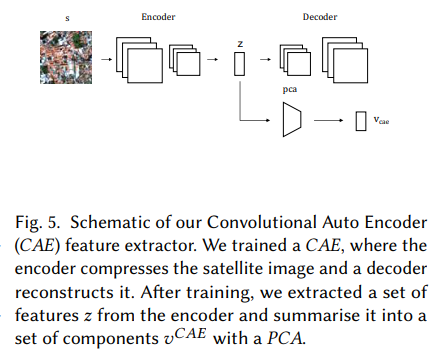
위성 이미지릿에서 시각적 특징을 추출하기 위해 표준 컨볼루션 신경망(CN N )[32] 아키텍처와 주성분 분석(PCA)으로 구성된 파이프라인을 적용했습니다. 이미지 i ∈ I가 주어지면, 여기서 I는 이미지릿의 집합이며, 우리의 목표는 상관관계가 없고 정렬된 시각적 구성 요소의 벡터를 검색하는 것입니다. 비지도 컨볼루션 자동 인코더(CAE) 기능 추출기(그림 5).
그림 5. CAE(Convolutional Auto Encoder) 특성 추출기의 개략도. 인코더가 위성 이미지를 압축하고 디코더가 이를 재구성하는 CAE를 훈련했습니다. 훈련 후 인코더에서 특징 z 세트를 추출하고 PCA를 사용하여 구성요소 세트 v CAE로 요약합니다.
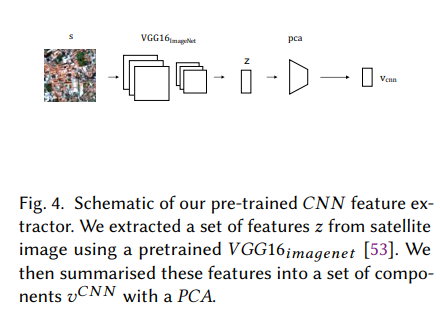
사전 훈련된 CNN 특징 추출기. 우리는 VGG16 [53] CNN 아키텍처(그림 4)(ImageNet [48]에서 사전 훈련된 가중치)를 채택했습니다. imagelet i가 주어지면 마지막 하나의 완전 연결 레이어(4,096개 특징)(zi)의 출력을 추출하고 PCA를 사용하여 이러한 기능 zi를 연관되지 않은 구성 요소 vCNN의 희소 집합으로 요약했습니다.
그림 4. 사전 훈련된 CN N 특징 추출기의 개략도. 사전 훈련된 VGG16 imaдenet [53]을 사용하여 위성 이미지에서 특징 z 세트를 추출했습니다. 그런 다음 이러한 기능을 PCA가 있는 구성 요소 집합 v C N N으로 요약했습니다.
CAE(Convolutional Autoencoder) 기능 추출기. VGG16 아키텍처는 "오버헤드 뷰" 위성 이미지에 대해 훈련되지 않았기 때문에 이미지렛에서 훈련할 수 있는 추가 아키텍처를 선택했습니다. 이 아키텍처는 합성곱 자동 인코더(CAE)[5, 41](그림 5)와 PCA [33]를 사용합니다. CAE는 두 개의 매개 변 수화된 기능, 결정적 인코더 fw(·) 및 결정적 디코더 Gu(·)로 구성된 감독되지 않은 접근 방식입니다. 컨볼루션 레이어는 인코딩 레이어가 이미지 i의 차원을 잠재 임베딩 zi로 축소하는 반면 디코딩 레이어는 차원을 재구성 i'로 다시 확장하는 곳에서 순차적으로 스택 될 수 있습니다. 순차 아키텍처는 그림 5에서 볼 수 있습니다. 다음[41]에서 softheencoderzi =Fw(i) 및 디코더 i′ = Gu(zi ) 매개변수는 i와 재구성된 버전 i′ =Gu(Fw(i)) 사이의 재구성 손실을 최소화하여 업데이트됩니다. 여기서 nbatch는 배치의 이미지 수이고 LREC는 재구성 손실입니다.
컨볼루션 오토 인코더는 배치 크기가 128인 500 Epoch에 대해 학습률이 0.001인 ADAM [31] 옵티마이저를 사용하여 위성 이미지로 훈련되었습니다. 광범위한 테스트 후에 우리는 임베딩 차원을 512로 선택했습니다. 손실이 0.01에서 안정화되는 압축과 더 낮은 재구성 손실 사이의 -off(표 2는 우리가 사용하게 된 아키텍처의 구현 세부 정보를 보고함). 훈련 후 훈련된 인코더를 사용하여 위성 이미지렛에서 더 낮은 차원 임베딩을 추출한 다음 PCA를 사용하여 상관되지 않은 구성 요소 vCAE로 요약합니다.
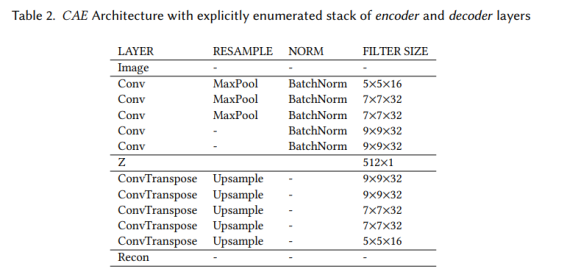
VGG16 및 CAE 모두에 대해 ncomp =12,...,64 PCA 구성 요소를 평가(섹션 4)에서 실험했으며 6개 도시의 모든 데이터를 사용할 때 ncomp = 16 구성 요소를 사용하는 것이 최상의 결과를 산출한다는 것을 발견했습니다. 논문의 나머지 부분에서는 단순화를 위해 vCNN과 vCAE를 모두 실험하는 동안 vi를 사용하여 이미지렛 특징 벡터를 표시합니다.
3.2 Computing Six Vitality Proxies and Urban Vitality for a District
3.2 지구에 대한 6개의 활력 프락시 및 도시 활력 계산
우리는 De Nadai et al. 의 이전 작업을 기반으로 합니다. [14]. 저자들은 이탈리아의 6개 도시에서 제인 제이콥스 이론을 실증적으로 검증했습니다. 그들은 Jacobs가 정의한 도시 활력의 네 가지 생성자, 즉 토지 이용, 소규모 블록, 경제 활동의 다양성, 사람들의 집중이 실제로 도시 활력을 예측했음을 보여주었습니다.
우리의 위성 이미지에서 우리는 경제 활동의 다양성(도시 형태의 속성이 아님)이나 사람들의 집중도(위성 이미지가 공개 데이터이지만 중간 해상도이기 때문에)를 추정할 수 없습니다. 대조적으로, 토지 이용과 작은 블록은 위성에서 잠재적으로 볼 수 있는 4개 중 2개의 활력 생성기입니다. 그 정도를 테스트하기 위해 6개 도시(밀라노, 플로렌스, 볼로냐, 토리노, 팔레르모, 로마)에 대해 계산된 6개의 활력 프락시(표 3)로 운영했습니다.
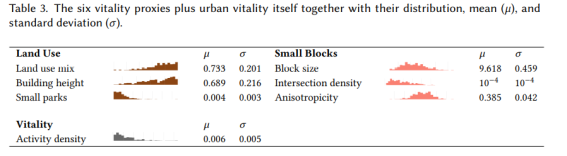
표 3. 분포, 평균(μ) 및 표준 편차(σ)와 함께 6개의 활력 프락시와 도시 활력 자체.
이 여섯 가지 프락시를 설명하기 전에 분석의 공간 단위에 대한 선택을 정의하고 동기를 부여해야 합니다. 우리는 이전 연구[14]에서와 같이 분석 단위로 지역(또는 지역)을 사용했습니다. 지구는 인구 조사 지역으로, 사회 경제적 조건에 따라 그룹화된 인접 블록(즉, 거리 세그먼트로 구분된 섹션)으로 구성됩니다. 이탈리아 맥락에서 지구는 인구(13,000명에서 18,000명 사이)와 크기(평균 면적 2.47 km2) 측면에서 비교할 수 있습니다(표 1). 우리 데이터 세트의 6개 도시에 대한 지구의 평균 인구 밀도는 km2당 10K입니다. 이러한 매개변수는 Jacobs가 그녀의 책[28]에서 논의한 공간 영역의 매개변수에 해당합니다.
3.2.1 토지 이용. Jacobs는 한 지역의 주요 용도의 혼합이 활력을 촉진한다고 제안했습니다 [28]. 주요 용도 카테고리의 예로는 주거용 건물, 사무실 공간, 산업, 엔터테인먼트, 교육, 레크리에이션 및 문화 시설이 있습니다. 도시 토지 사용 범주에 대한 가장 포괄적인 데이터 세트 중 하나는 테스트 도시를 포함하여 유럽 대부분의 도시에 대해 생성된 Urban Atlas2입니다. 20개의 토지이용등급(녹색도시, 체육·레저시설, 도시 직물 등)에 대한 정보를 제공한다. Urban Atlas는 Google Earth, Open Street Map 및 수동으로 수집된 현장 데이터와 같은 보조 데이터와 함께 고해상도 위성 이미지로 구축됩니다.
토지 사용 혼합. Urban Atlas에서 먼저 각 구역의 토지 사용 혼합을 계산했습니다. Manaugh와 Kreider [40]에 따르면 토지 사용 혼합은 도시 토지 사용의 세 가지 주요 범주의 엔트로피로 계산할 수 있습니다. i) 주거, ii) 상업, 산업, 기관 및 정부, iii) 레크리에이션, 공원 및 물. 우리는 공식을 사용했습니다.
토지이용 카테고리.
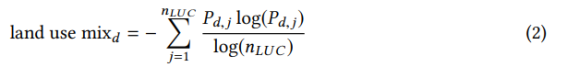
작은 공원. 사람들이 시간을 보내거나 그냥 걷도록 유인함으로써 작은 공원은 활력을 촉진합니다 [4, 28]. 각 구역 d에 대해 가장 가까운 작은 공원(면적 < 1km2)에서 모든 블록의 평균 거리를 계산했습니다.
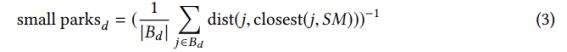
여기서 Bd는 구역 d의 블록 집합이고, 가장 가까운(j, Y)는 블록 j의 중심에서 집합 Y의 지리적으로 가장 가까운 요소를 찾는 함수이고, SM은 작은 공원의 집합이며, dist(a, b)는 다음과 같습니다. 두 요소의 중심 사이의 지리적 거리 및 b.
건물 높이. Jacobs는 낮은 건물 높이가 레스토랑, 상점 및 기타 서비스의 개업을 촉진하고, 이는 차례로 보행자 활동을 촉진한다고 주장했습니다 [28]. Sung et al. [56]은 건물 높이에 대한 프락시로 한 구역의 건물당 평균 층 수를 사용했으며 다음과 같이 계산되었습니다.
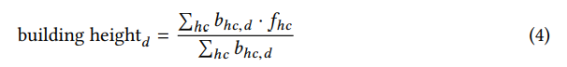
여기서 bhc, d는 구역 d에서 높이 범주 hc에 속하는 건물의 수이고 fhc는
높이 카테고리 hc에 해당하는 층 수. 건물 바닥에 대한 데이터를 수집하기 위해 이탈리아 국립 통계 연구소(ISTAT) 3을 사용했습니다.
3.2.2 작은 블록.
여섯 가지 활력 프락시 중 다른 하나는 보행 가능성과 교차 사용 기회를 증가시키는 것으로 밝혀진 작은 블록입니다.
블록 크기. 구역의 블록 크기 변수는 모든 블록 Bd의 평균 크기로 정의할 수 있습니다.
지구 내 d:
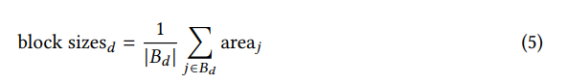
교차 밀도. 무작위 접촉을 증가시켜 도시 활력에 기여하는 작은 블록 범주의 또 다른 변수는 교차 밀도입니다.

이방성. 이방성은 방향과 간격에 관한 기하학적 모양의 불규칙성을 나타냅니다. 블록의 크기는 비교적 작을 수 있지만 이방성 모양을 나타내면(즉, 측면 중 하나가 다른 측면보다 상당히 긴 경우) 측면 중 하나와 접촉할 가능성이 줄어듭니다. 블록 Bd의 평균 이방성 [36]으로 각 구역 d에 이방성을 할당했습니다.
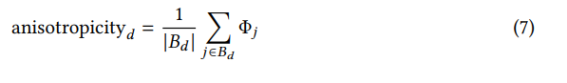
여기서 Φj는 블록 j의 면적과 외접원 Cj의 면적 사이의 비율입니다.

3.2.3 도시 활력.
우리는 모바일 인터넷 활동을 도시 활력의 대리인으로 사용했습니다. 통화 및 SMS 활동에 대한 휴대전화 데이터와 달리 이러한 유형의 데이터는 휴대전화를 활발히 사용하지 않을 때도 사람들의 존재를 감지하여 지역 내 이동성을 더 잘 추적할 수 있습니다. 이탈리아 최대 이동통신사인 Telecom Italia Mobile(총 휴대전화 사용자 기반의 34%)은 2014년 2월부터 10월까지의 데이터를 제공했습니다.

활동 밀도. 각 지역에 속하는 인터넷 연결 수를 추정하기 위해 라디오 방송국의 위치를 기반으로 한 Voronoi 다각형 세트[18]로 공간을 표현했습니다. 시간 t에서 각 구역 d의 인터넷 활동을 추정하기 위해 구역 d에 속하는 모든 폴리곤 p에 대한 인터넷 연결 수를 계산했습니다.
사용일. 인터넷 연결 수는 비율인 Ap∩d에 의해 가중치가 부여됩니다.
여기서 p는 다각형이고 Rp는 일반적인 인터넷 연결 수입니다.
p의 d구역에 해당하는 면적의 Ap∩d (Ap∩d는 d구역에 속하는 p의 면적, Ap는 p의 총면적
앱
지역). p의 전체 면적에서 W로 표시된 해역을 제거했습니다(즉, Ap∩W 제거).
3.3 Combining District Feature Vectors with Urban Vitality
3.3 지역 특성 벡터와 도시 활력의 결합
imagelet 수준의 기능과 지역 수준의 레이블을 준비한 후 두 데이터 세트를 다음과 같이 결합했습니다. 먼저 다음 절차에 따라 이미지렛을 지구에 할당했습니다. 이미지렛이 여러 구역과 겹치는 경우 가장 많이 겹치는 구역에 이미지렛을 할당했습니다. 그림 6은 토리노에서 이미지렛을 할당하는 방법을 보여줍니다. 9,115개의 원본 이미지렛 중 대부분이 도시 경계를 벗어났습니다. 이 절차를 통해 우리는 총 2,146개의 이미지렛으로 각 도시에 대해 서로 다른 비율의 이미지렛을 할당할 수 있었습니다(도시별 분석은 표 1에 표시됨). 그러나 우리는 여전히 모든 9K 이미지렛을 사용하여 자동 인코더 기능 추출기 CAE(섹션 3.1에서 설명)를 훈련했습니다. 이 이미지렛은 우리의 훈련 및 테스트 세트의 기초를 구성했습니다.
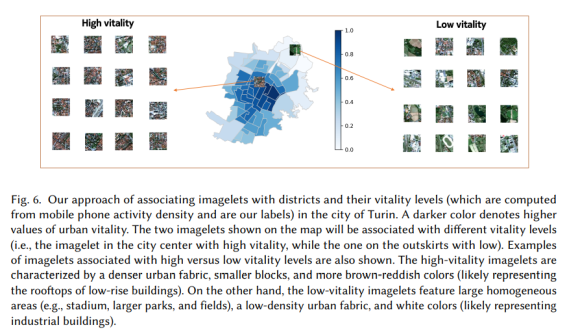
그림 6. 토리노 시에서 이미지렛을 지구 및 활력 수준(휴대전화 활동 밀도에서 계산되고 우리의 레이블임)과 연관시키는 접근 방식. 짙은 색일수록 도시의 활력이 높다는 것을 의미합니다. 지도에 표시된 두 개의 이미지렛은 서로 다른 활력 수준과 연관됩니다(즉, 도심의 이미지렛은 활력이 높고 외곽의 이미지렛은 활력이 낮음). 높은 활력 수준 대 낮은 활력 수준과 관련된 이미지렛의 예도 표시됩니다. 활력이 높은 이미지렛은 밀도가 높은 도시 패브릭, 더 작은 블록, 더 갈색-적색 색상(저층 건물의 옥상을 나타낼 가능성이 높음)이 특징입니다. 반면에, 낮은 활력 이미지렛은 균일한 넓은 영역(예: 경기장, 더 큰 공원 및 들판), 저밀도 도시 패브릭 및 흰색(산업용 건물을 나타낼 가능성이 있음)을 특징으로 합니다.
둘째, 이미지렛 특성을 이용하여 각 도시와 각 구역에 대해 이전 연구와 유사한 방식으로 대표 구역 특성 벡터를 도출하였다 [26]. 각 지구 d ∈1,..., N, wetokfeature vectorsvi1, vi2,... vind ∈Rncomp(여기서 ncomp는 섹션 3.1에서 논의된 PCA 구성 요소의 수)의 이미지릿 i1, i2, .., ind 에 대해 하나의 이미지로 집계했습니다.
구역 이미지릿 특징 벡터의 n 구성 요소에 걸쳐 σ 는 또한 크기 comp d의 벡터입니다.
imagelet의 구성 요소에 걸쳐 표준 편차를 취하여 유사한 방식으로 ncomp를 얻습니다.
벡터, pd는 쌍 사이의 평균 피어슨 상관관계를 취하여 얻은 숫자입니다.
2는 지역 중심을 나타냅니다(즉, 중심점의 경도/위도). 처음 4개의 요소 그룹은 중심 경향, 분산,
연관(pd) 및 크기(nd). [26]과 비교하여 시각적 기능 세트를 추가로 강화했습니다.
이전 연구에 따르면 지리적 위치 특성, 즉 지구 중심이 있음을 보여주었습니다.
포함은 이미지렛의 공간적 위치를 인코딩하고 성능을 향상합니다 [10, 57]. 따라서 특징 벡터 xd의 k번째 요소를 xdk로 표시하면 다음과 같습니다.
첫 번째 ncomp 요소는 모든 지역 이미지렛 벡터의 ncomp -th 구성요소(각각)의 평균값입니다.
위치(ncomp + 1)에서 위치(2 · ncomp)까지의 요소는 모든 지역 이미지렛 벡터의 ncomp -번째 구성요소의 표준편차 값입니다.
위치 (2 ncomp + 1)의 요소는 이미지렛 벡터의 피어슨 상관관계입니다.
(2 ncomp + 2) 위치에 있는 요소는 해당 지역의 이미지렛 개수이며,
마지막 두 요소는 지구 중심의 경도 및 위도 좌표입니다.
구역 특징 벡터를 정의하는 우리의 방법은 구역 크기나 이미지렛의 수와 관계없이 길이가 동일하다는 좋은 속성을 가지고 있습니다(즉, xd ∈ Rm, 여기서 m = 2ncomp + 1 + 1 + 2).
마지막으로 수집된 6개의 프락시(표 3) 각각에 대해 구역 d에 해당하는 값 yd를 취하고 이 값을 구역의 특징 벡터 xd와 연결했습니다. 이 결합된 데이터 세트는 훈련 및 테스트 세트를 구성했습니다.
4 EVALUATION
훈련 및 테스트 데이터를 준비한 후 두 가지 주요 평가 실험을 설정했습니다. 이 실험의 주요 목표는 위성 이미지에서 1) 표 3의 6개 프락시(섹션 4.4) 및 2) 도시 활력 자체(섹션 4.5)의 두 가지 종류의 양을 추정할 수 있는지 여부를 테스트하는 것이었습니다.
4.1Setup
생성된 지역 특징 벡터를 사용하여 표 3의 6개 프락시 각각에 대해 종속 변수가 초기에 6개 활력 프록시 각각인 회귀 작업을 만들었습니다. 도시활력의 대용으로 사용되는 활동 밀도를 포함한 다양한 변수의 분포는 표 3과 같다. 활동 밀도와 토지 이용범 주의 변수는 편향되어 있으므로 자연로그를 이용하여 로그 변환하였다. 또한 변수의 척도가 상당히 다양하기 때문에 회귀 모델을 실행하기 전에 나중에 상대적 중요성을 비교할 수 있도록 표준화하고 정규화했습니다.
4.2 Regression methods
역 특징 벡터 xd ∈ Rm(섹션 3.3에서 계산됨) 및 해당 레이블 y ∈ R(섹션 3.2에서 계산됨)이 주어지면 다음 형식의 선형 회귀 모델을 사용하여 yˆ 예측을 목표로 했습니다.
yˆ=w+wx1+...+wxm, d=1,..., N, (10) d01 dmd
여기서 계수 wj는 모델에 의해 학습되고 m은 지역 특징 벡터 크기이고 N은 총 지역 수입니다.
||yd − Xdw||2를 최소화하는 일반 최소 제곱 회귀(Ordinary Least Squares regression) 외에도, 여기서 Xd는
모든 구역 벡터 xd의 행렬을 나타냅니다. 우리는 또한 ElasticNet 회귀를 실험했습니다.
이는 1 ||yd − Xdw||2 + αρ||w||1 + α(1−ρ) ||w||2를 최소화하며, 여기서 w는 가중치 2N 2 2 2의 벡터입니다.
w = (w1,..., wm ), α 및 ρ는 L1(계수 크기의 절댓값) 또는 L2(계수 크기의 제곱 값) 페널티를 제어하는 매개변수입니다. 우리는 희소성을 장려하기 때문에 ElasticNet을 선택했습니다. 즉, 중요하지 않은 변수를 자동으로 제거하고 그런 방식으로 고차원 위성 특징 벡터를 더 잘 처리합니다 [38]. 활력을 예측하면서 매개변수 공간에 걸쳐 그리드 검색을 수행했으며 이러한 매개변수가 α = 0.01 및 ρ = 0.1에서 가장 잘 작동하는 것으로 나타났습니다.
또한 SVR(Support Vector Regression)[8] 방법도 실험했습니다. 매개변수 공간에 대한 그리드 검색은 최적의 하이퍼 매개변수 C = 1.0, deдree = 3, γ = scale 및 상수 ε = 0.0001 세트를 사용하여 RBF 커널을 산출했습니다.
마지막으로 극단적인 그래디언트 부스팅[21], 즉 XGBoost 회귀를 사용하여 결정 트리의 앙상블도 테스트했습니다. 우리가 다룬 것과 같은 작은 구조화된 데이터 세트에서 의사 결정 트리 기반 알고리즘은 가장 성능이 좋은 방법 중 하나로 간주됩니다. 매개변수 그리드 검색 시 약한 학습자 350명, 학습률 0.01, 허브 손실, 최대 트리 깊이 3을 사용했습니다.
R2
4.3 Metrics
각 회귀 방법이 위성 기능에서 도시 변수를 얼마나 잘 예측했는지 평가하기 위해 회귀 방법에 사용된 두 가지 표준 메트릭인 결정 계수(R2), 수정된 버전(R2) 및 평균 절대 오차(MAE)에 의존했습니다. ). 간단히 말해서, R2는 입력 변수(이미지 특징)에서 예측 가능한 대상 변수(도시 변수)의 분산 비율을 adj로 측정하는 반면, 조정된 버전 R2는 입력 adj 변수의 수와 훈련 데이터 크기를 설명하므로 새로운 입력 변수의 도입으로 인한 R2의 잘못된 증가. MAE는 참 값과 예측 값(l 값 쌍의 집합) 사이의 오류를 측정합니다.
4.4 Predicting the Six Vitality Proxies
선정된 회귀 기법을 적용하여 Table 3의 6개 프락시 각각을 추정하고 추정 값을 이용하여 2단계 회귀분석을 통해 도시활력을 예측하였다. 각 방법에 대해 5겹 교차 검증을 100번(k-겹 반복) 수행하고 점수를 평균화했습니다. 이는 낮은 표본 크기에서 높은 분산이 주어졌을 때 안정적인 결과를 얻기 위해 수행됩니다.
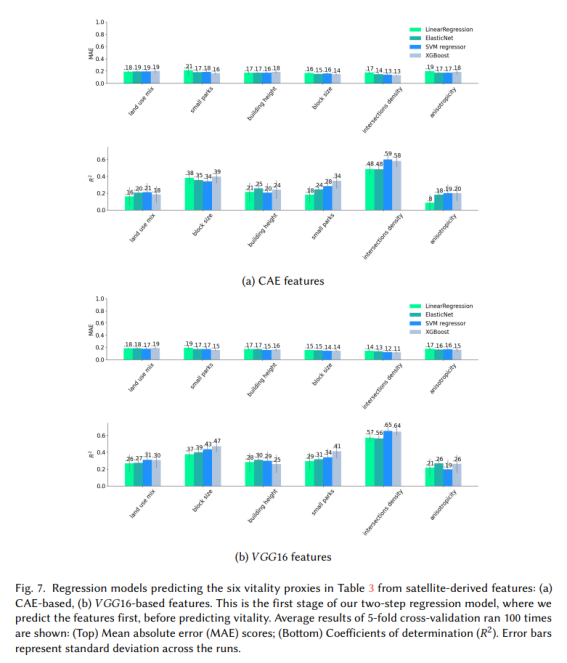
그림 7. 위성에서 파생된 특징에서 표 3의 6가지 활력 프락시를 예측하는 회귀 모델: (a) CAE 기반, (b) VGG16 기반 특징. 이것은 2단계 회귀 모델의 첫 번째 단계로, 활력을 예측하기 전에 먼저 기능을 예측합니다. 100회 실행된 5중 교차 검증의 평균 결과가 표시됩니다. (상단) 평균 절대 오차(MAE) 점수; (하단) 결정계수(R 2
). 오차 막대는 실행에 따른 표준 편차를 나타냅니다.
첫 번째 단계의 결과는 그림 7에 나와 있습니다. 시작 관찰은 다양한 기능(VGG16 대 CAE 기반)이 변수 전반에 걸쳐 비교적 유사한 패턴을 생성한다는 것입니다. 즉, 둘 다 교차 밀도와 블록 크기를 가장 잘 예측합니다. 그러나 CAE가 위성 이미지에 대해 훈련되었고 VGG16이 일반 이미지에 대해 훈련되었다는 사실에도 불구하고 VGG16 기능은 모든 변수에 대해 전반적으로 더 나은 성능을 보였습니다. 이는 데이터 세트(총 9K 이미지렛)의 상대적으로 작은 크기 때문일 가능성이 높으며 훈련을 위해 더 큰 데이터 세트를 사용하면 CAE 기능이 경쟁력을 가질 수 있습니다. 따라서 지금부터 VGG16 기능에 대한 결과에 대해 논의합니다. 6개의 프록시 중에서 이방성은 예측하기 가장 어렵습니다. SVR과 XGBoost는 전체적으로 가장 성능이 좋은 두 가지 방법입니다. 예측하기 어려운 또 다른 변수는 건물 높이입니다(SVR의 R2 점수는. 30이고 XGBoost의 R2 점수는. 24 임). 다른 네 가지 변수에 대해 SVR은 토지 사용 혼합에 대해. 31, 블록 크기에 대해. 43, 소규모 공원에 대해. 33, 교차 밀도에 대해 최대. 65의 R2 점수로 예측할 수 있었습니다. 육안으로 이미지에서 볼 수 있기 때문에 무엇보다도 예측하기 쉽습니다.
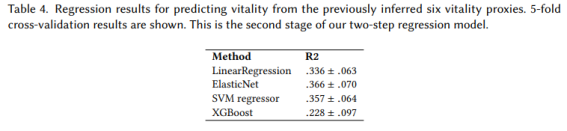
두 번째 단계에서는 이전에 추정한 6개의 프락시로부터 간접적으로 활력을 예측할 수 있는지 여부를 연구했습니다. 특히 우리는 선택된 모든 변수를 고려하고 예측 벡터를 가져오고 동일한 회귀 모델을 적용하여 활력을 예측했습니다. 우리는 이 설정에서 가장 성능이 좋은 방법이 선형 회귀, 즉 ElasticNet(R2 =. 37 ±. 07)의 형태라는 것을 발견했습니다(표 4의 결과).
마지막으로 활력을 예측하는 6가지 변수의 상대적 중요성을 연구했습니다. 이러한 각 변수에 대해 ElasticNet에서 찾은 계수(표 5)를 살펴보면 활력에 긍정적인 영향을 미치는 가장 예측 가능한 변수는 교차 밀도(계수. 497)이며, 이는 De Nadai et al이 이전에 보고한 결과와 일치합니다. 알. [14]. 또한 작은 공원은 활력에 긍정적인 영향을 미치고 블록 크기는 활력에 부정적인 영향을 미칩니다. 건물의 평균 층수를 통해 정의되는 건물 높이도 중요합니다. 높이가 높을수록 1층에 레스토랑 및 상점과 같은 서비스를 생성할 기회가 적어지고 따라서 활력이 낮아집니다.
4.5 활력 예측
두 번째 실험에서는 위성 이미지의 시각적 특징에서 직접 활력을 추정하는 4가지 회귀 모델의 예측력을 평가했습니다. 먼저 각 모델에 대해 5중 교차 검증 실험을 수행했습니다(그림 8). 이전 실험 세트에서는 SVR과 XGBoost regressor가 최고의 모델이었으며 비슷한 성능을 보였습니다. 이 실험에서 SVR(R2 =. 55 ±. 03, MAE =. 12 ±. 00)이 XGBoost 조정보다 약간 더 나은 성능을 보였습니다.
(R2 =. 54 ±. 04, MAE =. 13 ±. 01).
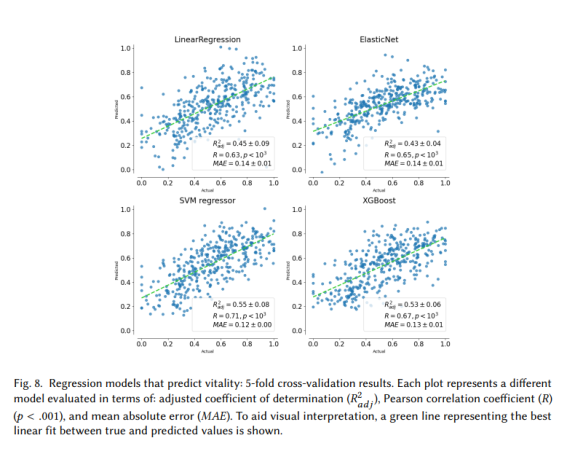
그림 8. 활력을 예측하는 회귀 모델: 5겹 교차 검증 결과. 각 플롯은 조정된 결정 계수(R adj), 피어슨 상관 계수(R)(p <. 001) 및 평균 절대 오차(MAE)와 관련하여 평가된 다른 모델을 나타냅니다. 시각적 해석을 돕기 위해 실제 값과 예측 값 간의 최적의 선형 맞춤을 나타내는 녹색 선이 표시됩니다.
마지막 실험에서 우리는 도시 활력 예측의 일반화 가능성을 연구했습니다. 즉, 일부 도시에서 모델을 학습하여 다른 (보이지 않는) 도시의 활력을 예측할 수 있는지 여부를 질문했습니다. 이를 위해 한 도시를 떠나는 검증 실험을 수행했으며 이전 실험에서 가장 성능이 좋은 모델인 SVR을 사용했습니다. 특히, 6개 도시 각각에 대해 5개 도시의 데이터에 대해 모델을 훈련하고 나머지 도시에서 테스트했습니다. 결과는 그림 9에 나와 있습니다. 모델의 예측력은 다양합니다. 밀라노와 플로렌스에서는 활력 분산의 50%와 61%를 각각 설명할 수 있지만 팔레르모와 로마에서는 설명된 분산은 다음과 같습니다. 각각 32%, 25%입니다. 활력을 예측할 때 위성에서 파생된 기능의 능력을 설명하기 위해 그림 10에서 6개 도시에 대한 실제 및 예측된 활력이 있는 지도를 보여줍니다.
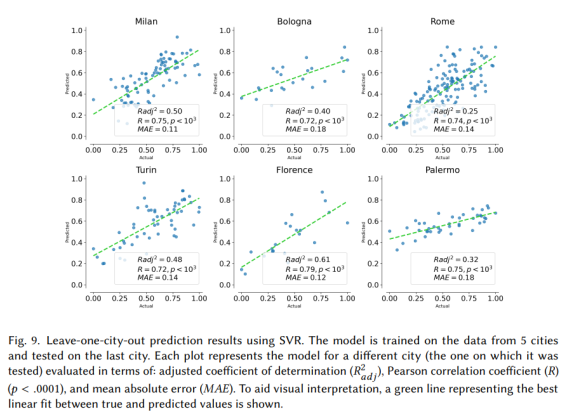
그림 9. SVR을 이용한 1개 도시 이탈 예측 결과. 모델은 5개 도시의 데이터에 대해 학습되고 마지막 도시에서 테스트됩니다. 각 플롯은 조정된 결정 계수(R 2 adj), Pearson 상관 계수(R)(p <. 0001) 및 평균 절대 오차로 평가된 다른 도시(테스트된 도시)에 대한 모델을 나타냅니다. (MAE). 시각적 해석을 돕기 위해 실제 값과 예측 값 간의 최적의 선형 맞춤을 나타내는 녹색 선이 표시됩니다.
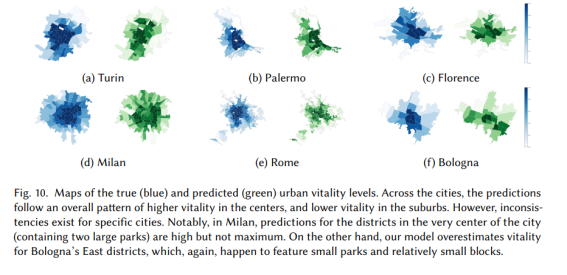
그림 10. 실제(파란색) 및 예측(녹색) 도시 활력 수준의 지도. 도시 전반에 걸쳐 예측은 중앙에서 더 높은 활력, 교외에서 더 낮은 활력의 전반적인 패턴을 따릅니다. 그러나 특정 도시에 대해 불일치가 존재합니다. 특히 밀라노에서는 도시 중심부(두 개의 큰 공원 포함)에 있는 지구에 대한 예측이 높지만 최대는 아닙니다. 반면에 우리 모델은 작은 공원과 상대적으로 작은 블록을 특징으로 하는 볼로냐 동부 지역의 활력을 과대평가합니다.
4.6 활력과 그 대리인 설명하기
지금까지 우리의 분석은 위성 데이터가 도시의 활력을 예측할 수 있고 다양한 정확도로 그렇게 할 수 있음을 시사했습니다. 모든 도시에서 테스트한 우리의 최고 성능 방법(SVR)은 0.55의 R2를 달성했으며 개별 도시에 대한 점수 범위는 Florence adj의. 61에서 Rome의. 25입니다. 이 섹션에서는 예측 정확도에 잠재적으로 영향을 미치는 요인(4.6.1항)과 모델의 추론과 해당 지역의 PoI 존재 사이의 연관성(4.6.2항)을 연구합니다.
4.6.1 활력 예측에 영향을 미치는 요소.
우리 실험에서 예측 점수가 가장 낮은 도시는 로마(R2 =. 25)입니다. 그것은 부분적으로 가장 작은 훈련 세트를 가지고 있기 때문일 수 있습니다. 조정
그 이유를 알아보기 위해 로마가 가장 많은 수의 지역구(표 1 참조)를 갖고 있으며, 하나의 도시 제외 평가에서 로마의 훈련 세트는 나머지 도시의 영역으로 구성되고 테스트 세트는 다음 영역으로 구성된다는 점을 고려하십시오. 로마. 결과적으로 로마는 다른 도시에 비해 훈련 세트가 가장 적습니다. 따라서 제한된 훈련 데이터가 조정된 R2 점수, 즉 R2에 영향을 미칠 수 있다고 추측할 수 있습니다. 실제로 로마의 조정되지 않은 R2는. 39로 R2보다 훨씬 높습니다. 조정 조정
이것이 다른 도시의 경우인지 여부를 연구하기 위해 예측 성능(R2 )이 훈련 데이터의 크기에 의존하는지 여부를 결정하기 시작했습니다. 도시의 훈련 데이터 크기 adj(TS로 표시)를 얻기 위해 나머지 5개 도시에서 지구 수 Nc를 합산했습니다(표 1 참조). 도시 전체에서 T S와 R2 사이에는 유의미한 상관관계가 없었습니다. 이는 예측 조정 점수가 일반적으로 훈련 데이터의 크기에 영향을 받지 않는다는 것을 의미합니다.

그림 11. 우리 모델이 활력 수준을 과대평가하고 과소평가한 로마의 잔차 및 위성 보기의 지도. 지도는 잔차, 즉 실제와 예측된 활력 수준 간의 차이를 보여줍니다. 파란색/빨간색은 모델이 실제와 비교하여 더 낮은/높은 활력 수준을 추정했음을 의미합니다. 예시 이미지렛은 우리 모델이 큰 공원, 강, 고속도로 및 경기장이 있는 지역의 활력 수준을 과소평가한 반면 건물 밀도가 높고 바다 근처의 지역의 활력 수준을 과소평가했음을 보여줍니다.
로마에 대한 예측 잔차.
다른 설명을 찾기 위해 로마에 더 집중했습니다. 그림 11은 잔차 맵, 즉 실제 활력 수준과 예측 활력 수준 간의 차이를 보여줍니다. 파란색/빨간색 영역은 우리 모델이 과소평가/과대평가한 영역입니다. 우리는 우리 모델이 다음에서 과소평가하는 경향이 있음을 발견했습니다. ii) 도심에 고대 랜드마크가 있는 지역. Jane은 국경 공백을 "보행자 활동에 적극적인 영향을 미치는 단일 대규모 또는 확장된 영토 사용 [...]의 경계"로 정의했습니다. 그녀의 이론에 따르면, 경계 진공은 실제로 맥락에 따라 높은 활력과 관련될 수 있습니다(“시각적 또는 모션 침투가 허용되면 [...] 장벽이 아니라 이음매가 되며, 두 영역이 함께 꿰매어지는 교환 라인") 및 낮은 활력(국경의 진공이 공공장소에서의 활동을 차단하는 경우). 우리의 분석은 국경 공백이 로마 중부 지역의 높은 활력과 관련이 있고 다른 도시의 낮은 활력과 관련되어 있음을 보여줍니다(예: 그림 6은 토리노의 낮은 활력 지역에서 국경 공백을 보여줍니다). 또한 로마의 전체 녹지 비율은 다른 어떤 도시보다 높습니다 4. Google 지도에서 과소평가된 중앙 위치를 조사하여 관광객들에게 인기 있는 고대 랜드마크(예: Largo di Torre Argentina, Foro Romano)도 포함되어 있음을 발견했습니다. 이 랜드마크는 다른 도시에서 일반적으로 볼 수 있는 도시의 특징이 아니며(특히 로마 지역의 크기가 상당히 제한된 토리노에서는 아님), 위성 이미지를 기반으로 하면 폐허와 유사하게 보일 수 있습니다. 그렇기 때문에 로마가 아닌 다른 도시에서 훈련된 모델이 관광객들 사이에서 인기가 있음에도 불구하고 로마의 해당 위치를 높은 활력으로 분류하는 방법을 배우지 못한 것일 수 있습니다.
반면, 이탈리아에서 가장 분주한 공항이 있는 바다(Fiumicino 시) 근처 남서쪽 지역에 주로 위치한 작은 블록과 밀집된 주택이 있는 지역에서는 우리 모델이 활력 수준을 과대평가하는 경향이 있음을 발견했습니다. 예상대로 소음 공해를 감안할 때 이 지역은 더 많은 중심 지역이 하는 것처럼 풍부한 야외 생활(소매점 포함)을 즐기지 않으며, Jacobs의 4가지 차원 중 하나인 혼합 경제 활동에 영향을 미칩니다.
Turin에 대한 예측 잔차. 예측 요인 분석을 로마와 비교하여 다른 지리적, 문화적, 경제적 환경으로 확장하고 모델이 더 잘 수행된 도시를 살펴보기 위해 다음으로 Turin을 조사했습니다. 토리노는 국가의 북쪽에 위치하고 있으며 로마와 같은 해변에 접근할 수 없습니다. 로마 인구의 3분의 1에 불과하지만 크기가 작기 때문에 인구 밀도가 3배 더 높습니다. 토리노에는 르네상스에서 로코코, 아르누보에 이르는 건축 양식의 건물, 성, 광장이 있으며 아름답고 역사적인 도심이 있습니다. 이 도시는 또한 여러 유명 이탈리아 자동차 회사의 본사와 두 개의 대형 축구 경기장을 보유하고 있습니다.
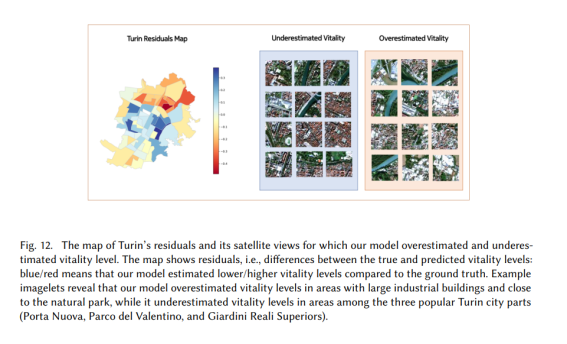
그림 12. 우리 모델이 활력 수준을 과대평가하고 과소평가한 Turin의 잔차 및 위성 보기의 지도. 지도는 잔차, 즉 실제와 예측된 활력 수준 간의 차이를 보여줍니다. 파란색/빨간색은 모델이 실제와 비교하여 더 낮은/높은 활력 수준을 추정했음을 의미합니다. 예시 이미지는 우리 모델이 큰 산업 건물이 있고 자연공원과 가까운 지역의 활력 수준을 과대평가한 반면 토리노의 인기 있는 세 지역(Porta Nuova, Parco del Valentino 및 Giardini Reali Superiors) 중 지역의 활력 수준을 과소평가했음을 보여줍니다.
그림 12는 Turin에서 예측된 활력 수준에 대한 잔차 맵을 보여줍니다. 이번에도 파란색/빨간색 영역은 우리 모델이 활력을 과소평가/과대평가한 영역입니다. 우리는 토리노에서 우리 모델이 다음을 과소평가하는 경향이 있음을 발견했습니다. 북쪽에는 조각상과 어린이 놀이기구가 있는 우아한 공원인 Giardini Reali Superiors가 있고 ii) 작은 운동 경기장인 Stadio Primo Nebiolo 옆에 있습니다. 토리노의 인기 있는 3개 도시(Porta Nuova, Parco del Valentino, Giardini Reali Superiors) 중 서로 도보 거리에 있는 지역은 실제로 보행자 이동성이 최대로 높습니다. 그러나 건물, 강 및 비교적 큰 공원이 혼합된 위성 이미지에서 우리 모델은 높은 것으로 추론했지만 여전히 최대 수준은 아닙니다. 흥미롭게도 Stadio Primo Nebiolo 경기장 주변 지역은 높은 활력과 관련이 있으며, 예를 들어 유벤투스 경기장은 북서쪽의 낮은 활력 지역에서 발견됩니다. 이것은 경계 진공이 활력과 다른 상호 작용을 할 수 있음을 다시 한번 확인시켜주며, 이 특정한 경우에 우리의 방법이 Stadio Primo Nebiolo 주변의 활력을 과소평가하게 만들었습니다.
반면에 우리는 우리 모델이 Po 강과 자연공원인 Riserva Naturale del Meisino e dell'Isolone Bertolla와 가까운 Turin 북동부 지역의 활력 수준을 과대평가하는 경향이 있음을 발견했습니다. 공원의 북쪽에는 농업 생산, 창고 및 일부 협동조합을 수용하는 여러 개의 대규모 산업 건물이 있습니다. 이러한 건물은 그림 12에서 과대평가된 활력에 대한 위성 이미지에서 볼 수 있듯이 흰색으로 보이며 인근에 주거용 주택을 나타내는 것으로 보이는 빨간색 건물과 공원이 혼합되어 있습니다. 우리는 이 경우 우리 모델이 이러한 다양성을 작은 공원에 가까운 오래된 건물과 새 건물이 혼합된 것으로 간주하여 이들의 활력을 과대평가했다고 추측합니다.
4.6.2 모델의 추론과 PoI 존재 간의 연관성. 우리의 예측 파이프라인은 시각적 특징을 추출하는 딥 러닝 방법으로 구성됩니다. 한 가지 문제는 추출된 특징이 해석 및 설명하기 어렵다는 것입니다. 이러한 추상적 이미지 특징과 지상의 실제 관심 지점 간의 연관성을 이해하기 위해 우리는 OpenStreetMap(OSM) 데이터베이스에 쿼리하고 이탈리아 6개 도시의 모든 관심 지점(PoI)을 수집했습니다. OSM은 PoI를 생활, 교육, 교통, 금융, 의료 및 엔터테인먼트의 6가지 넓은 범주의 편의 시설 5로 분류합니다. 활력은 한 지역의 인적 교통량을 측정하기 때문에 우리는 도시의 사회생활에 기여하는 대부분의 편의 시설을 포괄하는 생계, 교통 및 엔터테인먼트 범주에 중점을 두었습니다. 다음으로 섹션 3.3에서 설명한 2,146개의 이미지렛에 PoI의 위치를 매핑했습니다. 이 매핑을 사용하여 세 가지 PoI 범주 중 하나에 속하는 PoI의 총 수를 각 이미지렛에서 계산할 수 있었습니다. nsustenance, ntransportation 및 nentertainment PoI의 총 수를 포함하는 주어진 imagelet i에 대해 각 범주에 대한 PoI 점수를 계산했습니다.
로그 연산을 통해 PoI 수의 긴 꼬리 분포를 정규 분포로 변환할 수 있었습니다. 주어진 카테고리의 PoI가 0인 이미지렛에 대해 정의되지 않은 점수를 피하기 위해 1을 추가했습니다. 그런 다음 모든 이미지렛에 대해 계산된 이 세 가지 점수를 사용하여 모델의 추론과 현장의 PoI 범주 간의 연관성을 설명했습니다.
우리는 이미지렛을 두 개의 그룹으로 분할하여 기본 진실 값을 기반으로 활력과 각 프락시에 대해 매번 별도의 분할을 수행했습니다. 첫 번째 그룹에는 활력에 대한 ground truth 값 또는 그 프록시인 경우 하나가 상위 3분위수에 있는 모든 이미지렛이 포함되어 있습니다. 유사하게, 다른 그룹에는 하위 3분위 값이 있는 이미지렛이 포함되어 있으며 이를 하위 클래스라고 합니다. 그런 다음 높은 그룹과 낮은 그룹의 50%를 이미지릿의 훈련 세트로 샘플링하고 나머지 그룹을 테스트 세트로 유지했습니다. 그런 다음 훈련 세트에서 위성에서 파생된 기능을 사용하여 활력과 그 프록시를 예측하기 위해 이진 분류기 세트를 훈련했습니다. 모델의 성능은 5중 교차 검증 설정에서 AUC 점수가 작은 공원의 경우 .63 ± .07, 작은 블록의 경우 .88 ± .06, 작은 블록의 경우 .93 ± .06으로 원래 모델과 비슷했습니다. 활력. 그런 다음 이러한 훈련된 모델을 사용하여 이미지렛의 테스트 세트에 대한 활력 및 프록시에 대한 이진 클래스를 예측했습니다. 마지막으로, 이미지릿의 예측된 레이블과 지상에서 발견된 PoI 간의 관계를 정량화하기 위해 이미지릿 i가 상위 클래스에 속할 것으로 예측되고 ci = 1인 경우 예측된 클래스 레이블, 즉 클래스 ci = 1을 이진화했습니다. 0, imagelet i가 낮은 등급으로 예측되는 경우. 또한 방정식 (12)를 사용하여 주어진 이미지릿 i에 대한 범주 점수를 계산했습니다. 이 점수는 Ssiustenance, Stiransportation 및 Seintertainment로 다시 표시되었으며 [0, 1] 척도로 정규화되었습니다. 이 설정을 사용하여 OSM PoI 범주 점수가 주어지면 imagelet이 클래스 1에 속할 확률을 예측하는 로지스틱 회귀를 맞춥니다.
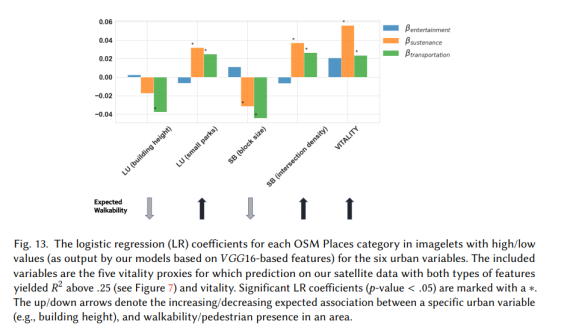
그림 13은 예측 변수인 생계, 교통 및 오락과 관련된 로지스틱 회귀 계수 β1, β2, β3의 값을 보여줍니다. β 계수의 값을 승산비로 해석할 수 있습니다. 각 예측자의 단위 차이에 해당하는 예측 차이의 상한을 얻기 위해 '4로 나누기' 규칙을 사용했습니다 [23](p. 82). 이것은 로지스틱 회귀에서 각 예측 변수의 계수를 4로 나누면 예측 변수의 각 단위 증가에 대한 가능성 Pr(ci = 1)의 증가에 대한 결론을 도출할 수 있다는 것을 의미합니다. 간단히 말해서, 우리는 종속 변수가 양의 클래스에 속할 확률의 백분율 증가를 정량화할 수 있습니다. 실제로 그림 13의 결과는 위성 기능이 장소 측면에서 의미 있는 통찰력을 포착한다는 것을 보여줍니다. 세 가지 장소 범주 모두 활력을 긍정적으로 예측합니다. 특히, 생계 카테고리에 대한 PoI 점수가 1% 증가할 때마다 imagelet이 높은 활력 클래스(+1.5%) 및 높은 교차 밀도 클래스(≈ +1%)에 속할 가능성이 높아집니다. 마찬가지로, 운송 카테고리에 대한 PoI 점수가 1% 증가하면 해당 이미지렛이 높은 블록 크기 클래스(-1%)에 속할 확률이 감소합니다. 생계 및 교통 카테고리의 PoI는 더 높은 교차로 밀도와 작은 공원의 존재 가능성을 모두 예측합니다. 또한 예상대로 이 두 범주는 높은 블록 크기(보행성을 권장하지 않는 큰 블록) 및 높은 건물 높이(고층 건물)와 음의 관련이 있습니다. 요약하면, 생계 및 운송 범주의 PoI와 관련된 결과는 기대치를 충족합니다. 그러나 엔터테인먼트 범주의 경우 이는 활력 및 해당 프락시 "블록 크기"의 경우에만 해당되며 다른 프락시에는 해당되지 않습니다. 이는 부분적으로 OSM 엔터테인먼트 카테고리 5가 높은 활력을 특징으로 하는 밀집된 도심에서 발견되는 장소(예: 분수, 영화관, 극장)와 낮은 활력을 특징으로 하는 경계 진공 역할을 하는 장소(예: 카지노, 도박, 컨벤션)를 포함하기 때문입니다. 센터).
5 토론 및 결론
우리는 공개적으로 사용 가능한 Sentinel-2 이미지에서 특징을 추출하고 도시 활력에 대한 6가지 프락시(즉, 간접 예측)뿐만 아니라 활력 자체(즉, 직접 예측)를 예측하는 딥 러닝 프레임워크를 제안했습니다. 프레임워크는 6개의 중간 해석 가능한 도시 프락시(36%)를 통한 간접적 예측보다 활력의 직접적인 예측(변량의 55%가 설명됨)에 더 잘 작동하는 것으로 나타났습니다. 이는 다음 세 가지 이유에 기인할 수 있습니다. i) 간접 예측에 의존하는 6가지 프락시가 활력을 완전히 포착하지 못합니다(예: 경제 활동과 사람들의 집중의 혼합이 포착되지 않음). ii) 예측 오류는 2단계 프로세스로 인해 발생합니다. 및 iii) 간접 예측에 의해 간과된 측면을 포착할 수 있는 원시 위성 기능에 의존하는 직접 예측.
실용적인 의미. 제시된 예측 능력은 선진국에서 도시 계획 개입을 지원하고 빠르게 성장하는 개발도상국에서 지속 가능한 개발 이니셔티브를 지원하는 데 도움이 될 수 있습니다. 구체적으로, 우리는 네 가지 주요 실제적 함의를 확인했습니다.
도시 대시보드의 위성 데이터. 기존 도시 대시보드 및 디지털 서비스는 휴대폰 데이터의 고주파 특성과 인구 조사 데이터의 저주파 특성 사이의 격차를 충분히 채울 수 있는 위성 데이터로 향상될 수 있습니다. 우리는 활력에 중요한 도시 환경의 일부 구조적 특징이 위성 데이터로부터 추론될 수 있음을 보여주었다. 이 데이터가 중간 수준의 공간 해상도(10m)로 공개되고 지속적으로 업데이트(5-7일마다)된다는 점을 감안할 때 도시 환경의 변화를 모니터링하고 도시 계획자/설계자 및 정책 입안자를 지원하는 데 사용할 수 있습니다. 그들의 결정과 계획. 이는 다른 유형의 도시 데이터에 대한 접근이 자주 부족한 개발도상국과 특히 관련이 있습니다.
위성 데이터에서 도시 측정에 대한 지침. 우리의 결과는 또한 보이지 않는 도시를 추론할 때 매우 다양한 지리 데이터를 갖는 것이 중요하며, 특히 이러한 새로운 도시가 훈련 데이터의 도시와 역사 또는 문화 측면에서 충분히 다른 경우에 중요합니다.
급속한 도시화 촉진. 제이콥스의 다양화 강조는 특히 오늘날의 세계화와 관련이 있습니다. 그녀의 이론은 아프리카의 도시 불평등[43], 초대형 이벤트에 대비한 빈민가 청소[25], 대만과 같은 효율적인 성장[20]에 대해 조명합니다. 우리의 접근 방식은 이웃 구조에 대한 동적 보기를 제공하고 세계화와 관련된 문제를 추적하는 데 도움이 될 수 있습니다.
디지털 지구. 전 세계적으로 활력을 추적하는 방법을 확장하면 물리적 환경과 사회 사이의 관계에 대한 공유된 이해를 가능하게 하는 지구에 대한 대화식 관점에 기여할 수 있습니다 [11, 24].
이론적 함의. 다른 국가에서 이탈리아에서 수행한 실험을 복제하려면 해당 국가에서 활력을 위한 대리인 역할을 할 수 있는 휴대전화 데이터를 얻어야 합니다. 그런 다음 우리는 활력을 포착하는 시각적 특징을 배울 수 있으며, 이를 통해 다양한 자연 및 문화 환경에서 생명력이 표현되는 방식의 미묘함을 발견할 수 있습니다.
제한 사항 및 향후 작업. Sentinel-2 데이터 세트의 개방성은 장점이지만 제한된 공간 해상도가 한계입니다. 더 높은 공간 해상도 데이터를 공개적으로 사용할 수 있다면 모델의 성능이 향상될 것입니다.
우리는 또한 모바일 인터넷 데이터에 의존하여 활력에 대한 프락시를 수량화했는데, 이는 또 다른 한계일 수 있습니다. 그러나 제공업체(Telecom Italia)의 시장 점유율이 34%로 국내 최대이므로 이러한 프록시가 우리 연구의 특정 맥락에서 실제 발자취에 가까운 근사치를 제공한다고 믿습니다. 보다 일반적으로 오늘날의 고도로 연결된 세계에서 모바일 활동은 사람들의 존재를 측정하는 가장 좋은 프록시 중 하나이며 [16, 45, 50, 55], 도시 활력을 추정하는 데 성공적으로 사용되었습니다 [14, 30].
데이터의 또 다른 한계는 휴대폰 데이터와 위성 데이터 사이의 시간적 지연과 관련이 있으며 우리의 경우 3년에 달합니다. 이 기간 동안 도시 활력의 일부 측면이 변경되었을 수 있습니다.
더욱이 본 연구는 이탈리아의 맥락에서만 이루어졌기 때문에 일반화 가능성에 의문을 제기할 수 있다. 그러나 5개 도시의 데이터에 대해 훈련된 모델이 나머지 도시의 활력 수준을 예측할 수 있다는 사실은 우리 접근 방식의 일반화 가능성을 말해줍니다. 적어도 유럽은 아니더라도 이탈리아 맥락에서 말입니다. 그러나 로마는 도전을 제기했습니다. 고대인 로마의 도심은 옛 것과 새 것이 독특하게 혼합되어 있는 반면 활력을 위한 우리의 대리인은 현대 도시 형태에 기반을 두고 있습니다. 근현대 도시 형태와 고대 도시 형태 사이의 유사한 유형의 갈등은 바르셀로나[15]에서도 발견되었으며, 인근 지역은 매우 다양한 역사적 혼합을 즐기는 경향이 있습니다. 우리의 모델이 보이지 않는 도시에 더 잘 일반화되기 위해서는 훈련 세트의 도시, 역사적, 문화적, 자연적 맥락에서 더 큰 다양성이 필요할 수 있습니다.
또 다른 한계는 우리 모델이 주로 실제보다 활력에 대한 잠재력을 포착하고 있으며, 드물기는 하지만 특정 상황에서 예측이 실제 활력 수준과 일치하지 않을 수 있다는 것입니다. 예를 들어, 전체 COVID-19 전염병 잠금 기간 동안 밀라노의 위성 이미지를 촬영한 경우(보행자 활동이 크게 제한되는 동안) 우리 모델은 여전히 평상시와 유사한 활력 수준을 예측할 것입니다. 그러나 이 제한은 대부분의 이전 작업과 공유되며 고해상도 위성 이미지(보행자 활동을 관찰할 수 있는)가 공개적으로 제공될 때마다 부분적으로 수정될 수 있습니다.
미래 작업의 또 다른 라인은 활력이 정의상 다면적 개념이라는 점을 감안할 때 다중 모드 데이터를 통합하는 것입니다. 예를 들어 상업 활동과 사람들의 집중을 캡처하는 다른 무료로 사용 가능한 데이터 세트와 위성 데이터를 융합하여 예측 정확도를 향상할 것으로 예상됩니다. 마지막으로 정확도를 손상시키지 않으면서 설명 가능한 예측을 얻으려면 설명 가능한 AI 방법이 추가로 연구되어야 합니다 [49].
출처 : https://arxiv.org/abs/2102.00848
Jane Jacobs in the Sky: Predicting Urban Vitality with Open Satellite Data
The presence of people in an urban area throughout the day -- often called 'urban vitality' -- is one of the qualities world-class cities aspire to the most, yet it is one of the hardest to achieve. Back in the 1970s, Jane Jacobs theorized urban vitality a
arxiv.org
